
前言
在【课程总结】day24(下):大模型部署调用(vLLM+LangChain)一文中,我们曾学习到大模型需要借助 vLLM 进行部署。本章我们将介绍另外一个较火的部署组件 Xinference。
Xinference简介
Xinference 是一个高效的推理引擎,旨在加速深度学习模型的推理过程。它支持多种模型格式,并提供灵活的部署选项,适用于各种应用场景。
部署方法
准备环境
第一步:登录趋动云,新建一个项目
第二步:上传bge-m3模型
具体方法不再赘述,可以查看文章【产品体验】趋动云上使用LLaMaFactory进行模型微调的流程体验
第三步:进入开发环境
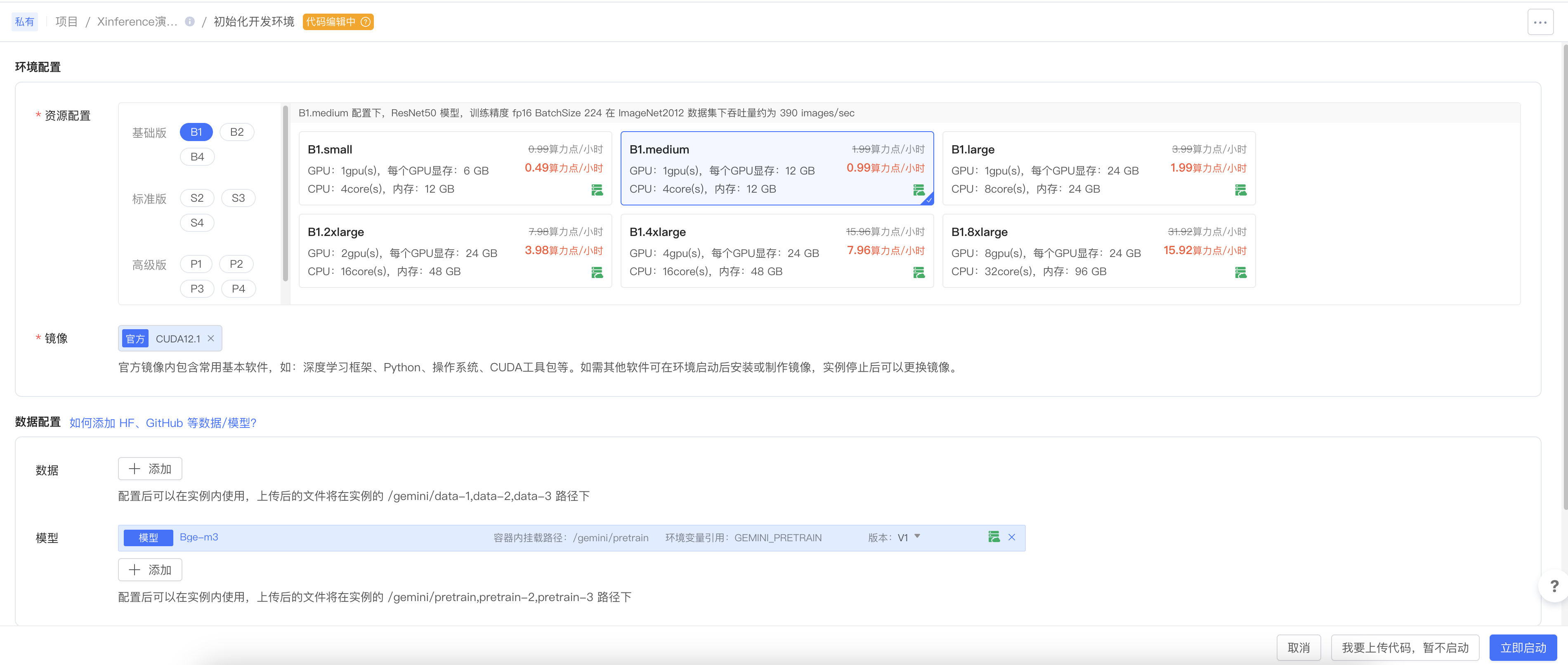
说明:
- 根据实际测试,镜像最好选择CUDA12.1的官方镜像,该镜像在后续安装引擎和依赖时,不会存在兼容性问题。
安装引擎
第四步:安装引擎
pip install "xinference[transformers,vllm]"说明:
- Xinference有多种引擎,此处我们选择Transformers和vllm引擎。
第五步:安装依赖
pip install sentence-transformers启动Xinference
第六步:启动 Supervisor
xinference-supervisor -H 0.0.0.0第七步:新建一个terminal,启动 Worker
xinference-worker -e http://127.0.0.1:9997 -H 0.0.0.0第八步:映射9997端口
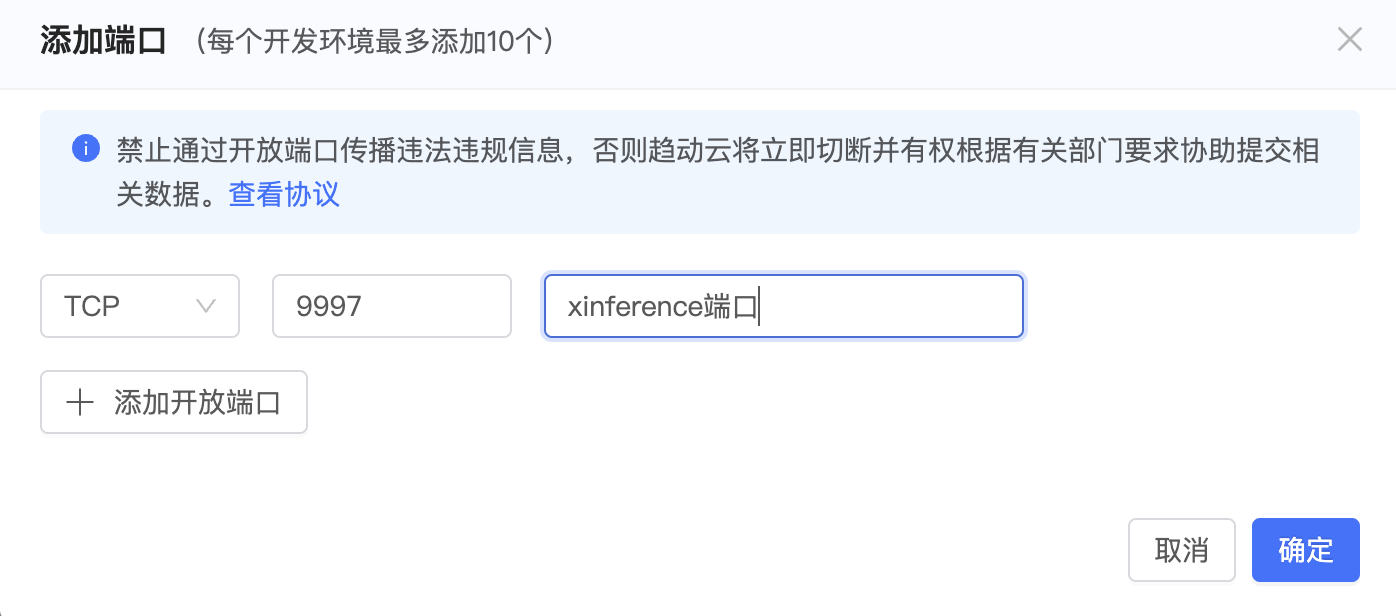
启动向量化模型
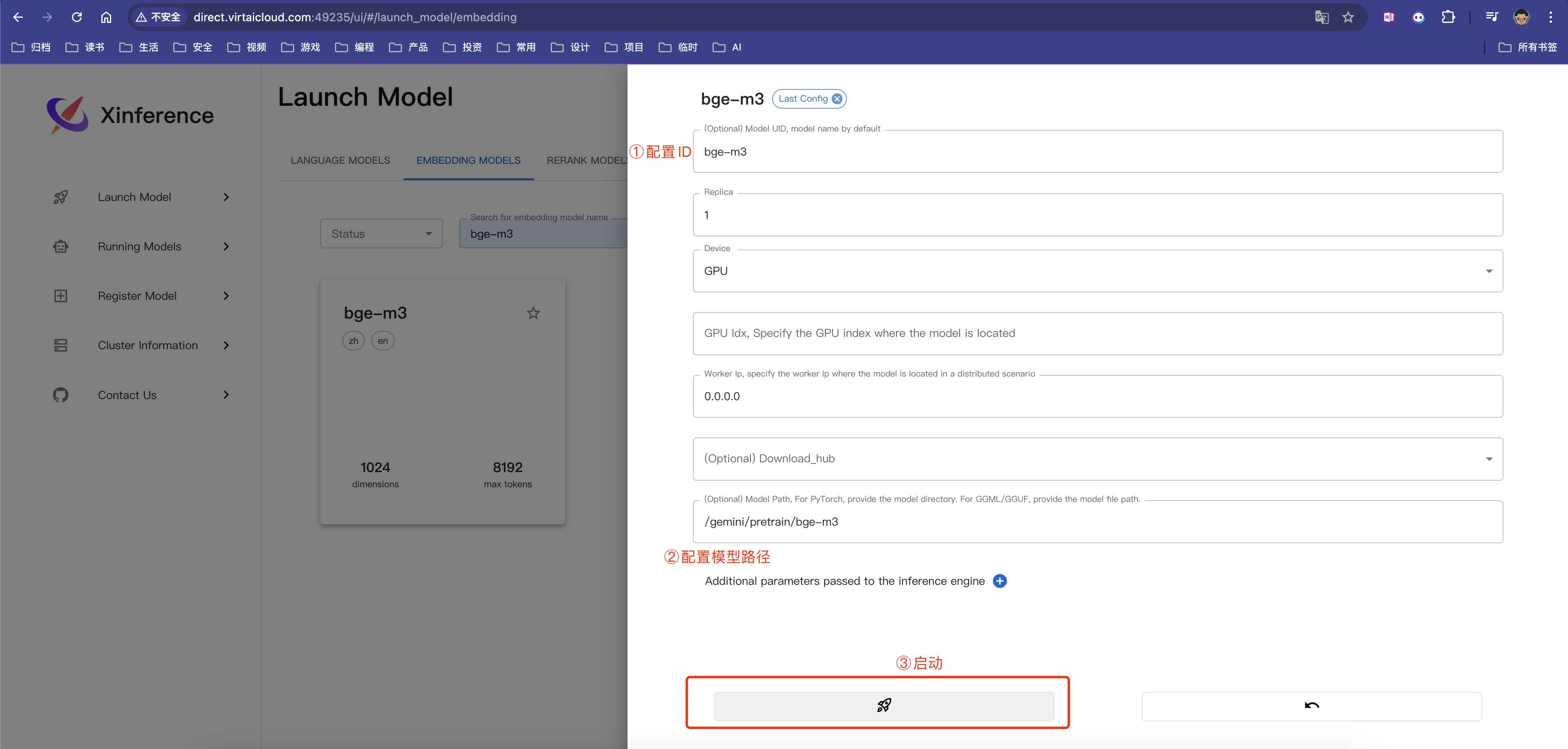
第九步:根据趋动云提供的地址,使用浏览器访问映射后的地址,例如:http://direct.virtaicloud.com:49235
第十步:在xinference提供的UI界面中,选择embedding模型,并配置bge-m3模型相关参数后,点击启动
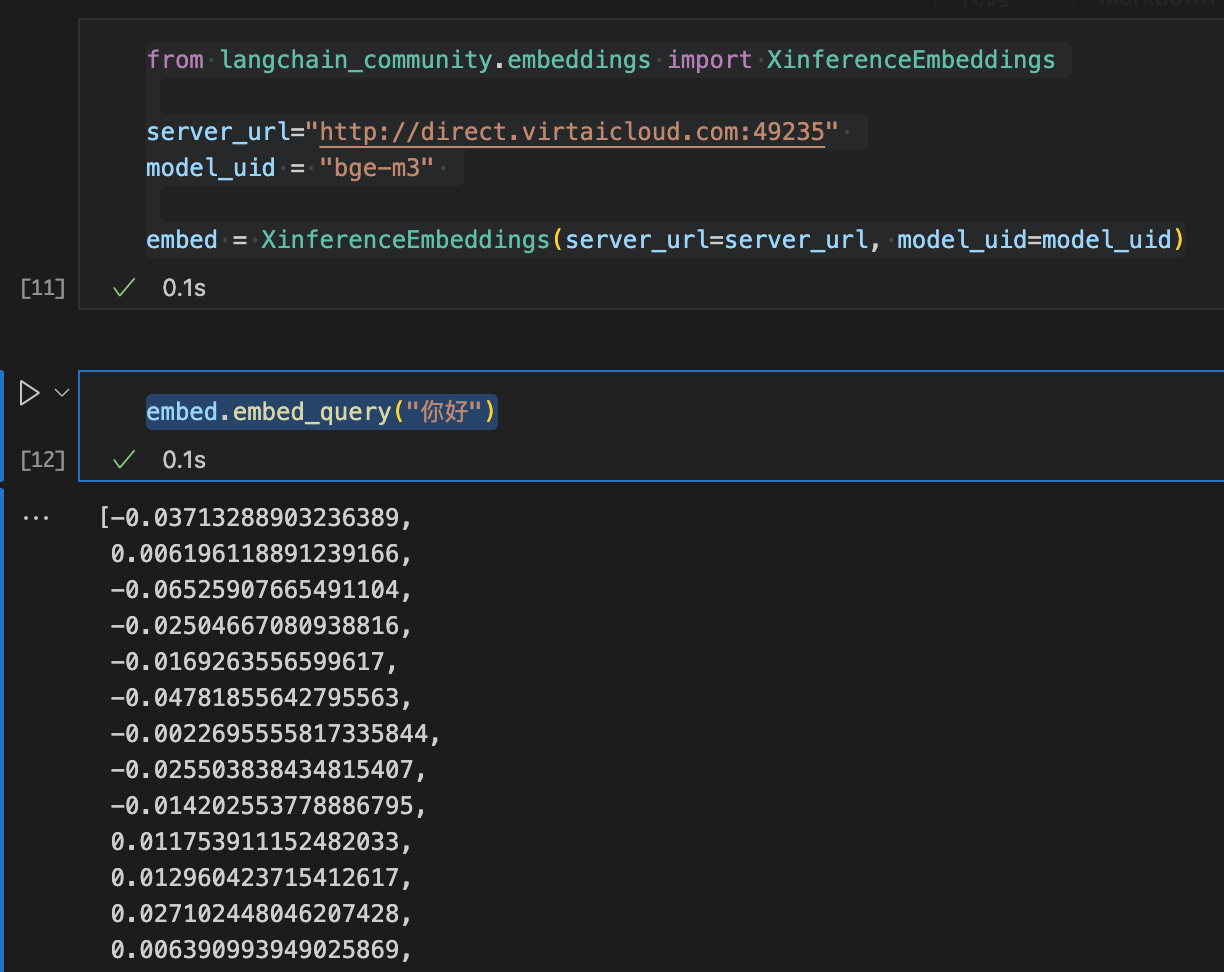
调用使用
from langchain_community.embeddings import XinferenceEmbeddings
server_url="http://direct.virtaicloud.com:49235"
model_uid = "bge-m3"
embed = XinferenceEmbeddings(server_url=server_url, model_uid=model_uid)
embed.embed_query("你好")运行结果:
其他模型启动方法
如果想使用Xinference部署其他模型,可以下载对应模型后,在UI界面中选择并配置。

内容小结
- Xinference是一个高效的推理引擎,其提供了比较便捷的UI界面进行模型部署。
- 部署的大致步骤为:
- 准备环境;
- 安装引擎和依赖;
- 启动Xinference;
- 在Xinference中配置模型并启动;
- 配置对外映射端口。
- Xinference除了支持向量化模型部署之外,还支持其他更多类型模型部署,例如:对话模型、多模态大模型、rerank模型等。
参考资料
欢迎关注公众号以获得最新的文章和新闻




