
前言
在【课程总结】Day16:对抗生成网络GAN中,我们曾接触了解了对抗生成GAN网络,本章将学习了解另外一种文生图的模型Diffusion扩展模型,并尝试搭建和试用stable Diffusion。
文生图简介
文生图(Text-to-Image)是一种人工智能技术,可以根据输入的文本描述生成相应的图像。其中近期比较火热的模型有Stable Diffusion,它基于扩散模型,将文本描述转化为图像。
资料
论文标题:《High-Resolution Image Synthesis with Latent Diffusion Models》
论文地址:https://arxiv.org/pdf/2112.10752
论文阅读理解
模型结构
论文要点
论文原文
To lower the computational demands of training diffusion models towards high-resolution image synthesis, we observe that although diffusion models allow to ignore perceptually irrelevant details by undersampling the corresponding loss terms [30], they still require costly function evaluations in pixel space, which causes huge demands in computation time and energy resources.
We propose to circumvent this drawback by introducing an explicit separation of the compressive from the generative learning phase (see Fig. 2). To achieve this, we utilize an autoencoding model which learns a space that is perceptually equivalent to the image space, but offers significantly reduced computational complexity.
Such an approach offers several advantages: (i) By leaving the high-dimensional image space, we obtain DMs which are computationally much more efficient because sampling is performed on a low-dimensional space. (ii) We exploit the inductive bias of DMs inherited from their UNet architecture [71], which makes them particularly effective for data with spatial structure and therefore alleviates the need for aggressive, quality-reducing compression levels as required by previous approaches [23, 66]. (iii) Finally, we obtain general-purpose compression models whose latent space can be used to train multiple generative models and which can also be utilized for other downstream applications such as single-image CLIP-guided synthesis [25].
论文翻译
为了降低高分辨率图像合成对扩散模型训练的计算要求,我们注意到,虽然扩散模型可以通过对相关损失项进行低采样来忽略感知上不相关的细节[30],但它们仍然需要在像素空间进行代价高昂的函数评估,这对计算时间和能源资源造成了巨大的需求。
我们建议将压缩学习阶段与生成学习阶段明确分开(见图 2),以规避这一缺点。为此,我们采用了一种自动编码模型,该模型学习的空间实际上与图像空间相当,但计算复杂度却大大降低。
这种方法有以下几个优点:(i) 通过撇开高维图像空间,我们得到的
DM在计算上更加高效,因为采样是在低维空间上进行的。(ii) 我们利用了DM从其UNet体系结构中继承下来的归纳偏差 [71],这使得它们对具有空间结构的数据特别有效,因此减轻了对以往方法所要求的激进的、降低质量的压缩级别的需求 [23, 66]。(iii) 最后,我们获得了通用压缩模型,其潜在空间可用于训练多个生成模型,也可用于其他下游应用,如单图像 CLIP 引导合成[25]。
论文理解
该论文提出了一种新的图像合成方法,称为潜在扩散模型(Latent Diffusion Model, 简称LDM),旨在通过在潜在空间中训练扩散模型来提高高分辨率图像合成的效率和质量。该方法结合了自动编码器的优点,减少了计算资源的消耗,同时保持了图像合成的高视觉保真度。该论文的核心要点是:
- 扩散模型的优势:扩散模型通过逐步去噪的方式生成图像,表现出色,尤其是在高分辨率图像合成上,避免了生成对抗网络(GAN)常见的模式崩溃和训练不稳定性问题。
- 潜在空间训练:通过在潜在空间(latent space)中训练扩散模型,LDM显著降低了计算复杂性,使得高分辨率图像合成变得更加可行。该方法允许模型在较低维度的空间中进行训练,从而加速了推理过程。
- 多模态条件机制:引入交叉注意力层,使得模型能够处理多种输入条件,如文本描述和边界框,这为图像合成提供了灵活性。
大致原理
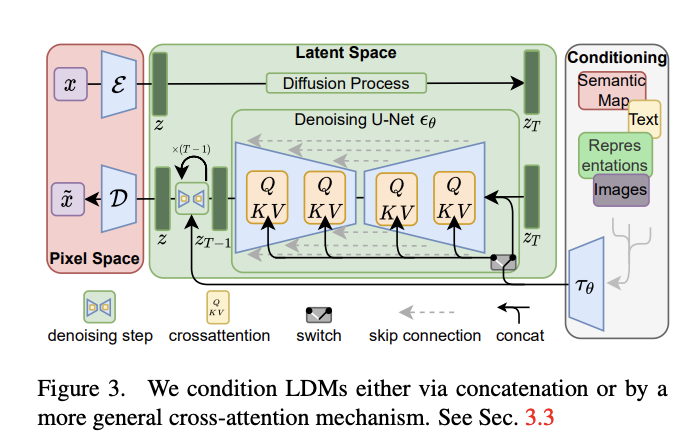
如模型结构图所示,其整体原理包含三个部分:
- 正向加噪过程:(在pixel space像素空间) 一张图像(x) –> 添加噪声(z) –> 添加噪声 … –> (在latent space潜在空间)变成纯噪声(Zt)
- 反向去噪过程:(在latent space空间)纯噪声(Zt) –> 去噪 –> 去噪 … –> (在pixel space空间)变成图像
- Unet结构:在反向去噪的过程中,采用了类似Unet的结构,通过采用类似Resblock的skip connection的方式传递梯度,使得在去噪过程中,可以保留一些细节。
- 交叉注意力:为了能够精准地控制从噪声转换为图的过程,通过交叉注意力机制,将Conditioning信息引入到Unet中。
- Conditioning信息:Conditioning中通过文本-中间表达-图像的方式,形成语义信息,进而通过交叉注意力进行融合。
论文中关于以上步骤的具体方式,由于数学内容过于硬核,能力有限,不做深入了解。
接下来,我们将部署一个stable Diffusion模型体验其功能。
部署 StableDiffusion 模型
准备环境
访问趋动云,创建一个开发环境
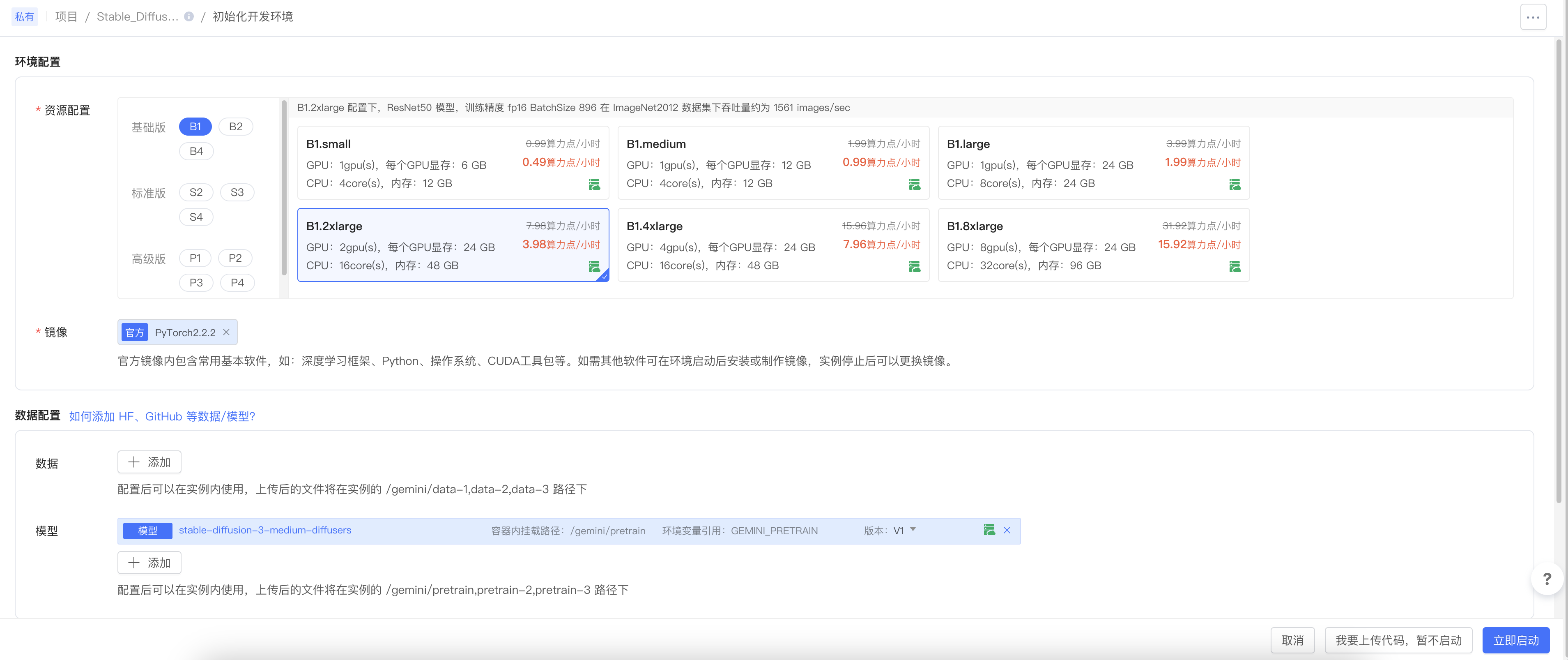
说明:
- 经过实测最好能够达到如下配置:显存:>24G
- 模型可以选择我已经上传的
stable-diffusion-3-medium-diffusers,也可以按照以下步骤下载模型。
下载模型
在 modelscope 上查找 stable diffusion模型并下载
# 确保lfs已安装
git lfs install
# 拉取模型
git clone https://www.modelscope.cn/AI-ModelScope/stable-diffusion-3-medium-diffusers.git说明:
- 下载模型到本地后,需要上传趋动云的模型中,具体方法请见准备模型。
安装diffusers
pip install -U diffusers调用模型
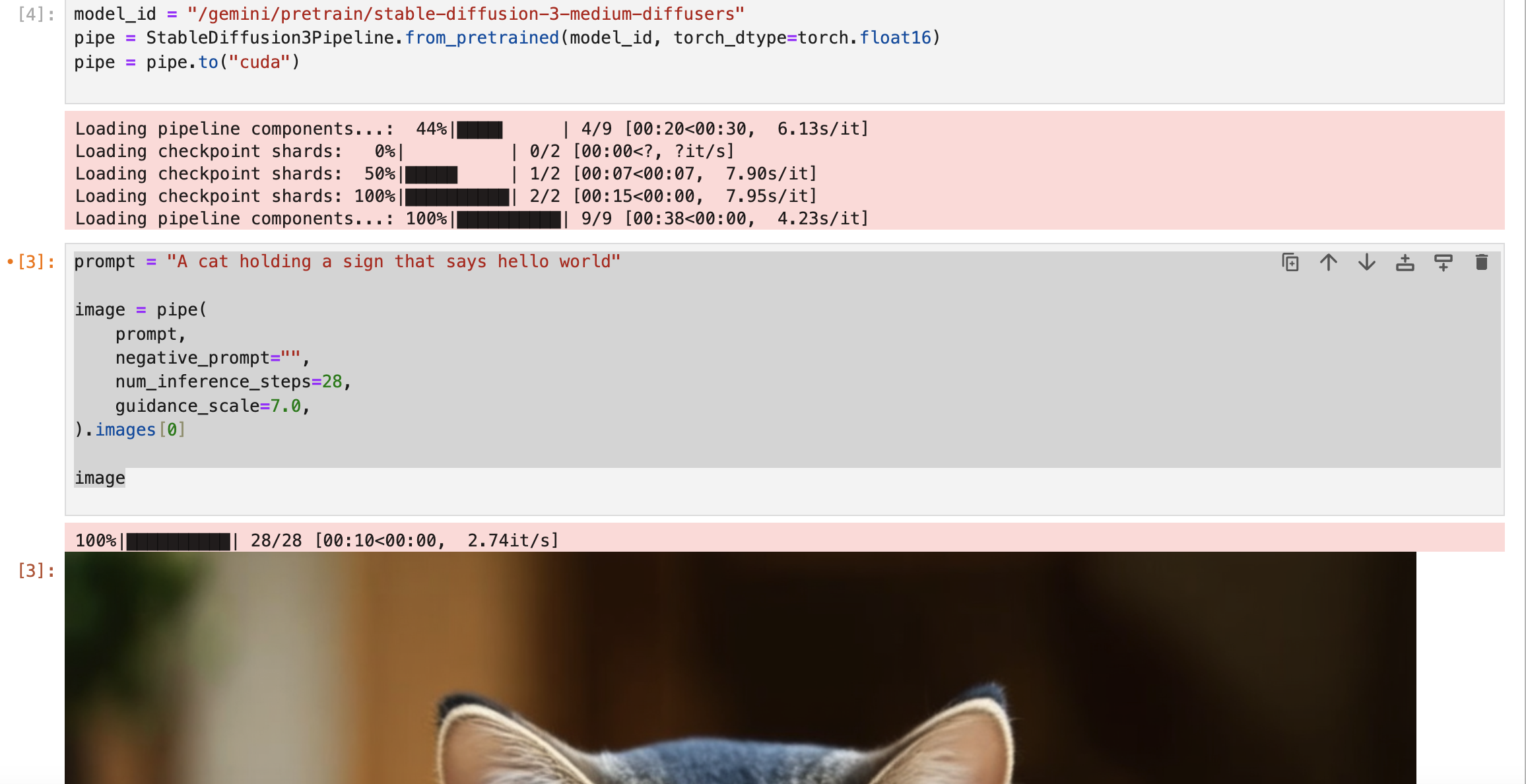
# 引入必要的库
import torch
from diffusers import StableDiffusion3Pipeline
# 设置模型本地路径
model_id = "/gemini/pretrain/stable-diffusion-3-medium-diffusers"
pipe = StableDiffusion3Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# 配置提示词
prompt = "A cat holding a sign that says hello world"
# 生成图片
image = pipe(
prompt,
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
# 显示图片
image运行结果:

显存占用
通过linux命令查看显存占用情况
nvidia-smi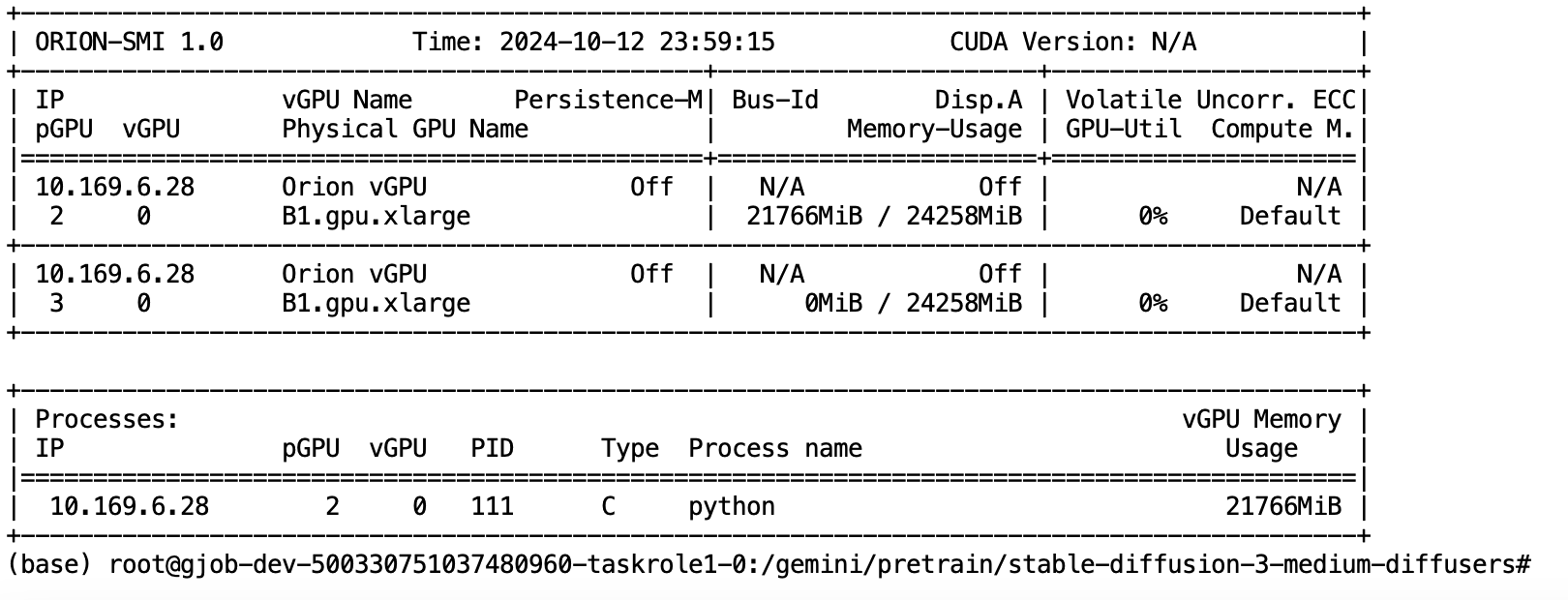
内容小结
- 文生图(Text-to-Image)是一种人工智能技术,可以根据输入的文本描述生成相应的图像。
- 文生图除了GAN模型之外,最新的还有Stable Diffusion模型。
- Stable Diffusion模型的大致原理为:
- 正向加噪过程:(在pixel space像素空间) 将一张图像(x) –> 不断添加噪声(z) –> 变成纯噪声(Zt)
- 反向去噪过程:(在latent space空间) 将纯噪声(Zt) –> 不断去噪 –> 变成图像
- Unet结构:在反向去噪的过程中,通过采用Unet结构,使得在去噪过程中,可以保留一些细节。
- 交叉注意力:为了能够精准地控制从噪声转换为图的过程,通过交叉注意力机制,将Conditioning信息引入到Unet中。
- Stable Diffusion的部署过程大致为:
- 配置显存大于24G的GPU环境
- 下载Stable Diffusion模型
- 安装diffusers
- 加载模型后,然后通过prompt提示词生成图片即可
参考资料
欢迎关注公众号以获得最新的文章和新闻




