
前言
在前一阶段课程中,我们学习了图像分割中的语义分割、实例分割、旋转目标检测等。这些图像分割算法都是有监督学习,而GAN(生成对抗网络)是一种特别的学习策略,其核心思想非常值得借鉴,所以本章将以GAN网络的代码为切入口,了解掌握其核心思想。
学习策略
人工智能方面的学习策略有两种:有监督学习和无监督学习。
有监督学习
定义:有监督学习是使用带标签的数据集进行训练。每个输入数据都有对应的输出标签,模型通过学习输入与输出之间的关系来进行预测。
举个例子:孩子的个人成长,有经验的家长为期规划了发展的路线,孩子在规划下有计划地学习成长,这属于有监督学习。
无监督学习
定义:无监督学习使用没有标签的数据集进行训练。模型试图发现数据中的模式或结构,而不依赖于任何预先定义的标签。
同样的例子:孩子在无监督学习下,是没有家长为期进行规划,而是经历社会"捶打"(做得好了有加分、做不好扣分),最终学习成长起来。
GAN的基础介绍
在上述的两种学习策略中,有一种特殊的、独立的学习策略:GAN(生成对抗网络)。
它由两个网络(生成器和判别器),通过对抗在竞争中共同发展。
- G:生成器(造假)
- D:鉴别器(打假)
- 训练过程:
- 两个网络刚开始都没有任何能力
- 在竞争中共同发展
- 最后两个网络能力都得到提升
举个例子:GAN网络就像警察和小偷,警察和小偷之间互相对抗。
GAN示例
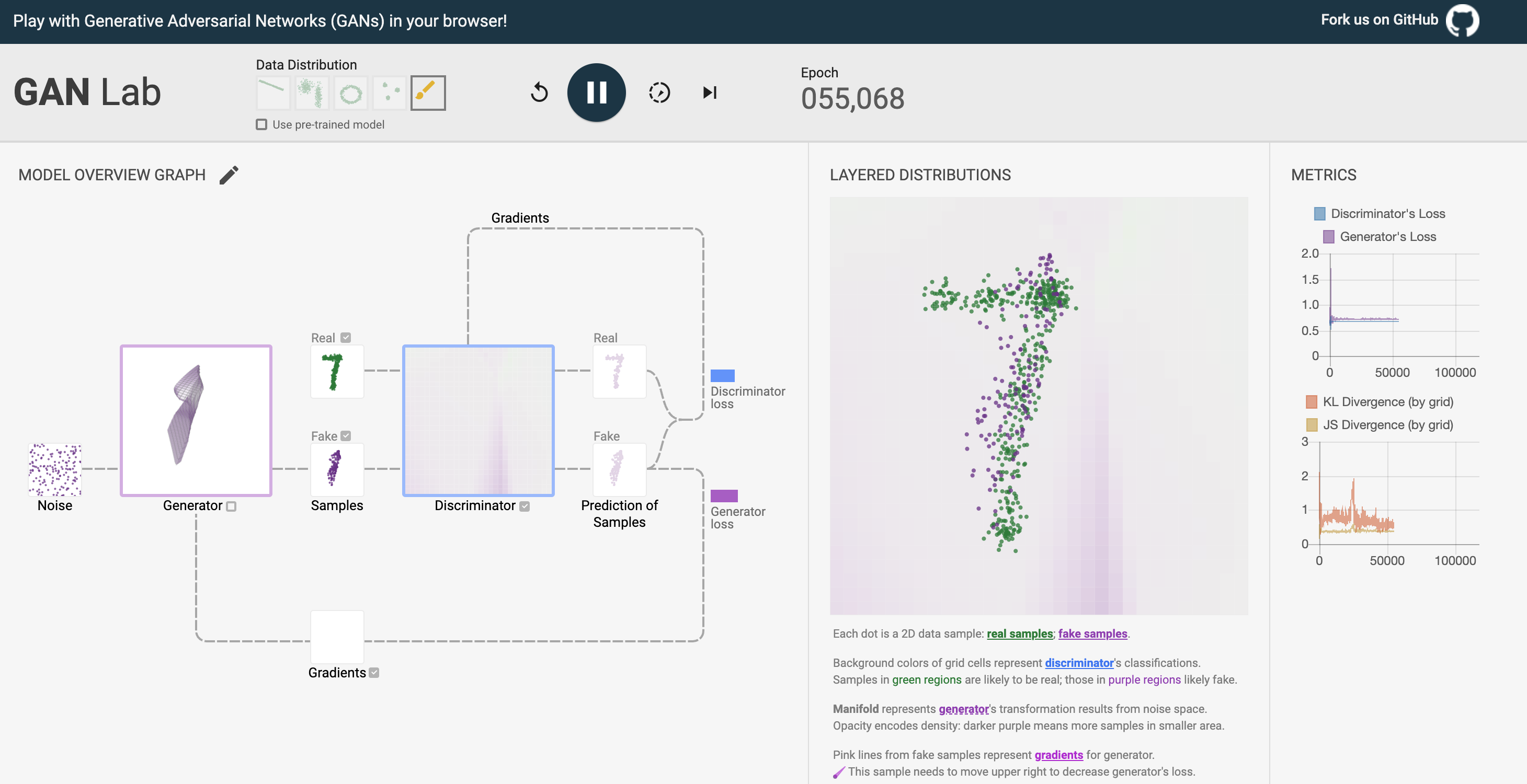
为了对GAN网络有个直观印象,我们可以参考Github上一个开源项目,对GAN有个初步认知。
页面地址:https://poloclub.github.io/ganlab/
示例目的
- 在页面中添加一个手写数字图像
- 通过训练模型来模拟手写数字图像
- 从而达到新图像与原来的风格类似,分不出真假
核心思想
论文地址:https://arxiv.org/pdf/1406.2661
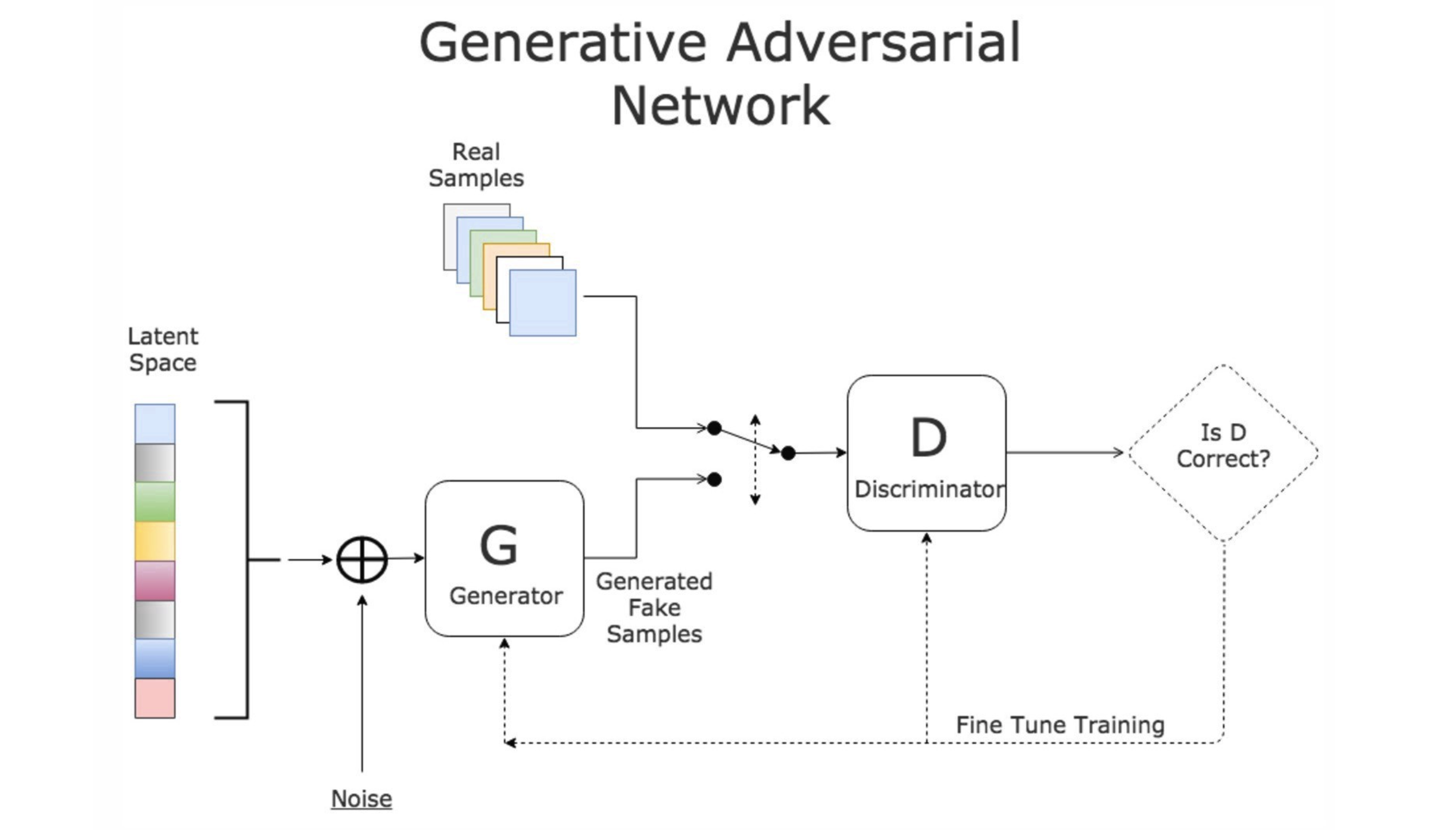
生成器(Generator):
- 作用:负责凭空编造假的数据出来。
- 目的:通过机器生成假的数据(大部分情况下是图像),最终目的是“骗过”判别器。
- 过程:G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
判别器(Discriminator):
- 作用:负责判断传来的数据是真还是假。
- 目的:判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”。
- 过程:D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
接下来,我们通过详细了解GAN网络的代码,深入了解其运行过程。
引入依赖
import torch
from torch import nn
from torch.nn import functional as F
import torchvision
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
from torch.utils.data import DataLoader
import os
import numpy as np
import matplotlib.pyplot as plt
# 判断当前设备是否GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device读取数据集
# 加载并预处理图像
data = datasets.MNIST(root="data",
train=True,
transform = transforms.Compose(transforms=[transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])]),
download=True)
# 封装成 DataLoader
data_loader = DataLoader(dataset=data, batch_size=100, shuffle=True)
- 备注:上述
transform = transforms.Compose的作用主要是进行数据增强,详细内容在补充知识部分展开介绍。
定义模型
定义生成器
"""
定义生成器
"""
class Generator(nn.Module):
"""
定义一个图像生成
输入:一个向量
输出:一个向量(代表图像)
"""
def __init__(self, in_features=100, out_features=28 * 28):
"""
挂载超参数
"""
# 先初始化父类,再初始化子类
super(Generator, self).__init__()
self.in_features = in_features
self.out_features = out_features
# 第一个隐藏层
self.hidden0 = nn.Linear(in_features=self.in_features, out_features=256)
# 第二个隐藏层
self.hidden1 = nn.Linear(in_features=256, out_features=512)
# 第三个隐藏层
self.hidden2 = nn.Linear(in_features=512, out_features=self.out_features)
def forward(self, x):
# 第一层 [b, 100] --> [b, 256]
h = self.hidden0(x)
h = F.leaky_relu(input=h, negative_slope=0.2)
# 第二层 [b, 256] --> [b, 512]
h = self.hidden1(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
# 第三层 [b, 512] --> [b, 28 * 28]
h = self.hidden2(h)
# 压缩数据的变化范围
o = torch.tanh(h)
return o定义鉴别器
"""
定义一个鉴别器
"""
class Discriminator(nn.Module):
"""
本质:二分类分类器
输入:一个对象
输出:真品还是赝品
"""
def __init__(self, in_features=28*28, out_features=1):
super(Discriminator, self).__init__()
self.in_features=in_features
self.out_features=out_features
# 第一个隐藏层
self.hidden0= nn.Linear(in_features=self.in_features, out_features=512)
# 第二个隐藏层
self.hidden1= nn.Linear(in_features=512, out_features=256)
# 第三个隐藏层
self.hidden2= nn.Linear(in_features=256, out_features=32)
# 第四个隐藏层
self.hidden3= nn.Linear(in_features=32, out_features=self.out_features)
def forward(self, x):
# 第一层
h = self.hidden0(x)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第二层
h = self.hidden1(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第三层
h = self.hidden2(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第四层
h = self.hidden3(h)
# 输出概率
o = torch.sigmoid(h)
return o构建模型
"""
构建模型
"""
# 定义一个生成器
generator = Generator(in_features=100, out_features=784)
generator.to(device=device)
# 定义一个鉴别器
discriminator = Discriminator(in_features=784, out_features=1)
discriminator.to(device=device)定义优化器
"""
定义优化器
"""
# 定义一个生成器的优化器
g_optimizer = torch.optim.Adam(params=generator.parameters(), lr=1e-4)
# 定义一个鉴别的优化器
d_optimizer = torch.optim.Adam(params=discriminator.parameters(), lr=1e-4)定义损失函数
"""
定义一个损失函数
"""
loss_fn = nn.BCELoss()筹备训练
定义训练轮次
# 定义训练轮次
num_epochs = 1000
获取数据的标签
"""
获取数据的标签
"""
def get_real_data_labels(size):
"""
获取真实数据的标签
"""
labels = torch.ones(size, 1, device=device)
return labels
def get_fake_data_labels(size):
"""
获取虚假数据的标签
"""
labels = torch.zeros(size, 1, device=device)
return labels定义噪声生成器
"""
噪声生成器
"""
def get_noise(size):
"""
给生成器准备数据
- 100维度的向量
"""
X = torch.randn(size, 100, device=device)
return X
# 获取一批测试数据
num_test_samples = 16
test_noise = get_noise(num_test_samples)噪声生成器的作用:因为我们需要监控模型训练的效果,所以将噪声固定下来,在训练过程中看同样的噪声最后给出的结果是否变得越来越好。
训练模型
"""
训练过程
"""
g_losses = []
d_losses = []
for epoch in range(1, num_epochs+1):
print(f"当前正在进行 第 {epoch} 轮 ....")
# 设置训练模式
generator.train()
discriminator.train()
# 遍历真实的图像
for batch_idx, (batch_real_data, _) in enumerate(data_loader):
"""
1, 先训练鉴别器
鉴别器就是一个二分类问题
- 给一批真数据,输出真
- 给一批假数据,输出假
"""
# 1.1 准备数据
# 图像转向量 [b, 1, 28, 28] ---> [b, 784]
# 从数据集中获取100个真实的手写数字图像
real_data = batch_real_data.view(batch_real_data.size(0), -1).to(device=device)
# 噪声[b, 100]
# 随机生成100个100维度的噪声,用于生成假图像
noise = get_noise(real_data.size(0))
# 根据噪声,生成假数据
# [b, 100] --> [b, 784]
fake_data = generator(noise).detach()
# 1.2 训练过程
# 鉴别器的优化器梯度情况
d_optimizer.zero_grad()
# 对真实数据鉴别
real_pred = discriminator(real_data)
# 计算真实数据的误差
real_loss = loss_fn(real_pred, get_real_data_labels(real_data.size(0)))
# 真实数据的梯度回传
real_loss.backward()
# 对假数据鉴别
fake_pred = discriminator(fake_data)
# 计算假数据的误差
fake_loss = loss_fn(fake_pred, get_fake_data_labels(fake_data.size(0)))
# 假数据梯度回传
fake_loss.backward()
# 梯度更新
d_optimizer.step()
# ----------------
d_losses.append((real_loss + fake_loss).item())
# print(f"鉴别器的损失:{real_loss + fake_loss}")
"""2, 再训练生成器"""
# 获取生成器的生成结果
fake_pred = generator(get_noise(real_data.size(0)))
# 生产器梯度清空
g_optimizer.zero_grad()
# 把假数据让鉴别器鉴别一下
# 把discriminator requires_grad = False
# 设置为不可学习
for param in discriminator.parameters():
param.requires_grad = False
d_pred = discriminator(fake_pred)
# 设置为可学习
for param in discriminator.parameters():
param.requires_grad = True
# 计算损失
# 把一个假东西,给专家看,专家说是真的,这个时候,造假的水平就可以了
g_loss = loss_fn(d_pred, get_real_data_labels(d_pred.size(0)))
# 梯度回传
g_loss.backward()
# 参数更新
g_optimizer.step()
# print(f"生成器误差:{g_loss}")
g_losses.append(g_loss.item())
# 每轮训练之后,观察生成器的效果
generator.eval()
with torch.no_grad():
# 正向推理
img_pred = generator(test_noise)
img_pred = img_pred.view(img_pred.size(0), 28, 28).cpu().data
# 画图
display.clear_output(wait=True)
# 设置画图的大小
fig = plt.figure(1, figsize=(12, 8))
# 划分为 4 x 4 的 网格
gs = gridspec.GridSpec(4, 4)
# 遍历每一个
for i in range(4):
for j in range(4):
# 取每一个图
X = img_pred[i * 4 + j, :, :]
# 添加一个对应网格内的子图
ax = fig.add_subplot(gs[i, j])
# 在子图内绘制图像
ax.matshow(X, cmap=plt.get_cmap("Greys"))
# ax.set_xlabel(f"{label}")
ax.set_xticks(())
ax.set_yticks(())
plt.show()运行结果:

核心代码说明:
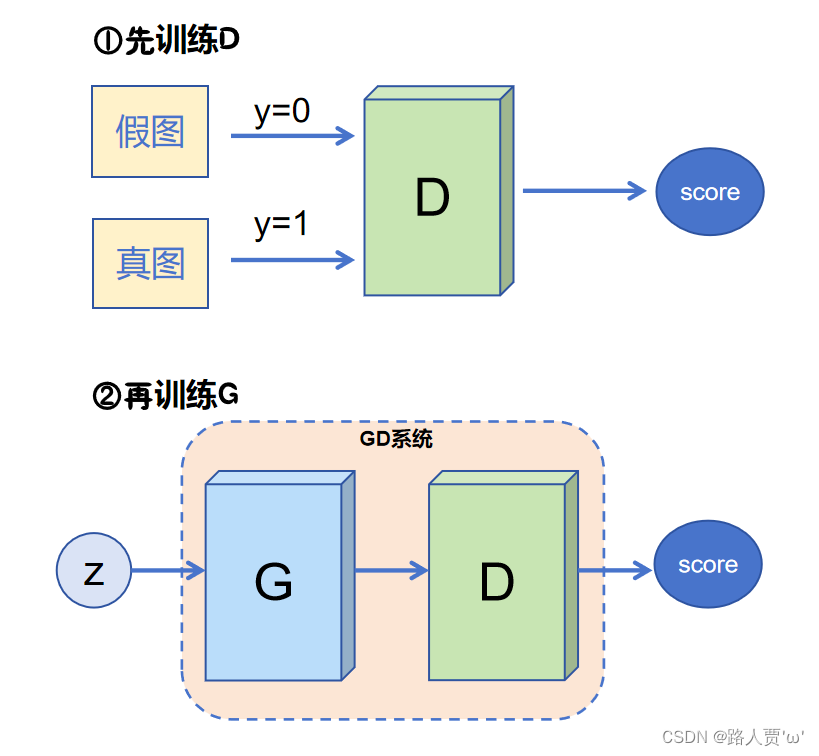
训练过程
- 随机生成一组潜在向量z,并使用生成器生成一组假数据。
- 将一组真实数据和一组假数据作为输入,训练判别器。
- 使用生成器生成一组新的假数据,并训练判别器。
- 重复步骤2和3,直到生成器生成的假数据与真实数据的分布相似。
核心代码
fake_data = generator(noise).detach():- 作用:是生成器生成一组假数据,并使用detach()方法将其从计算图中分离出来,防止梯度回传。
- 说明:(因为在训练鉴别器时,生成器只是工具人,其前向传播过程中记录的梯度信息不会被使用,所以不需要记录梯度信息)
g_loss = loss_fn(d_pred, get_real_data_labels(d_pred.size(0)))这里是体现对抗的核心代码,即:生成器训练的好不好,是要与真实数据的判别结果越接近越好。
补充知识
数据增强
在人工智能模型的训练中,采集样本是需要成本的,所以为了提升样本的丰富性,一般会采用数据增强的方式。
- 方式:在样本固定的基础上,通过软件模拟,来生成假数据,丰富样本的多样性
- 本质:给样本加上适当的噪声,模拟出不同场景的样本
- 说明:数据增强只发生在模型训练中,为了增加训练样本的多样性
transform介绍
在 PyTorch 中,transform 主要用于数据预处理和增强,特别是在图像处理任务中。transform 是 torchvision 库的一部分,能够对数据集中的图像进行各种转换,以便更好地适应模型训练的需求。以下是 transform 的主要作用
import torch
from torchvision import datasets, transforms
from PIL import Image
import matplotlib.pyplot as plt
# 读取本地下载的一张图片
img = Image.open('girl.png')
img
重设图片尺寸
resize = transforms.Resize((300, 200))
resize_img = resize(img)
resize_img运行效果:

中心裁剪
centercrop = transforms.CenterCrop(size=(200, 200))
center_img = centercrop(img)
center_img运行效果:

随机调整亮度、饱和度、对比度等
color_jitter = transforms.ColorJitter(brightness=0.5,
contrast=0.5,
saturation=0.5,
hue=0.5)
color_jitter(img)运行效果:

随机旋转
random_rotation = transforms.RandomRotation(degrees=10)
random_rotation(img)运行效果:

组合变换
Compose:可以将多个变换组合在一起,形成一个转换管道,方便批量处理。例如:
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(), # 将PIL Image转换为Tensor
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), # 将数据归一化到[-1, 1]之间
])
内容小结
- GAN(生成对抗网络)是一种特殊的学习策略,它由生成器和判别器组成,生成器生成假数据,判别器判断真假。
- 生成器(Generator)通过机器生成假的数据(大部分情况下是图像),最终目的是“骗过”判别器。
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”。
- 训练过程是:先训练判别器,再训练生成器。
- 训练判别器时,生成器是"工具人",所以需要使用detach()方法,将生成器生成的假数据从计算图中分离出来,防止梯度回传。
- 训练生成器时,判别器是"工具人",为了避免整个梯度消失,需要使用param.requires_grad = False设置为不可学习,判别完之后再使用param.requires_grad = True设置为可学习。
- 在人工智能模型训练过程中,通常会使用数据增强的方式,在样本固定的基础上,通过软件模拟,来生成假数据,丰富样本的多样性。
- transform:在 PyTorch 中,transform 主要用于数据预处理和增强,特别是在图像处理任务中。
参考资料
CSDN:适合小白学习的GAN(生成对抗网络)算法超详细解读
欢迎关注公众号以获得最新的文章和新闻



