前言
本文将介绍如何在趋动云平台上使用vllm部署Qwen2-0.5B-Instruct对话模型和BGE向量化模型,实现高性能的模型服务。
vllm简介
vllm官网
安装说明:https://docs.vllm.ai/en/latest/getting_started/installation.html
vllm环境依赖
官方建议:
- Python 3.12
- CUDA 12.1
环境准备
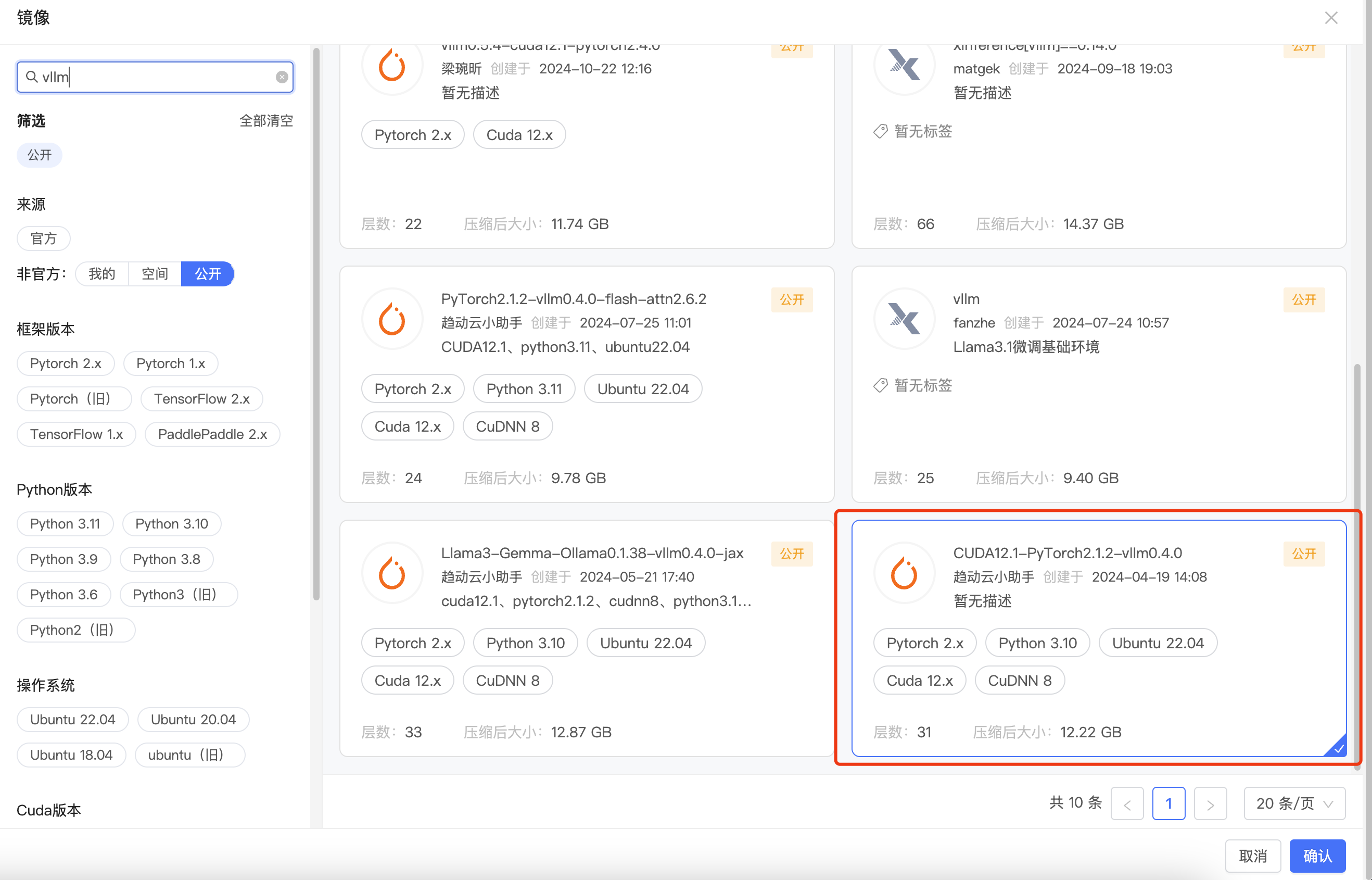
选择镜像
- 选择镜像环境
因为趋动云中通过pip install vllm会报错,所以我们在启动容器时,选择已经集成vllm的镜像。
安装vllm
(因为镜像中已经集成vllm,所以此处略过)
部署对话模型
下载模型
方式一:选择其他人上传并公开的模型。
在启动项目时,选择模型加载,在趋动云的公共模型中选择Qwen2.5-0.5B-Instruct模型。
方式二:自己下载模型。
切换至/gemini/code目录下,下载模型:
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git补充说明:
- 此处模型也可以使用趋动云的模型上传功能,因为篇幅限制,此处略过。
启动vllm
使用以下命令启动vllm服务:
python -m vllm.entrypoints.openai.api_server --model Qwen2.5-0.5B-Instruct --host 0.0.0.0 --port 8000运行结果:

注意事项:
- 启动
vllm命令时,它会在当前目录下寻找--model参数指定的模型文件夹,所以请确保当前目录下有Qwen2.5-0.5B-Instruct模型文件。
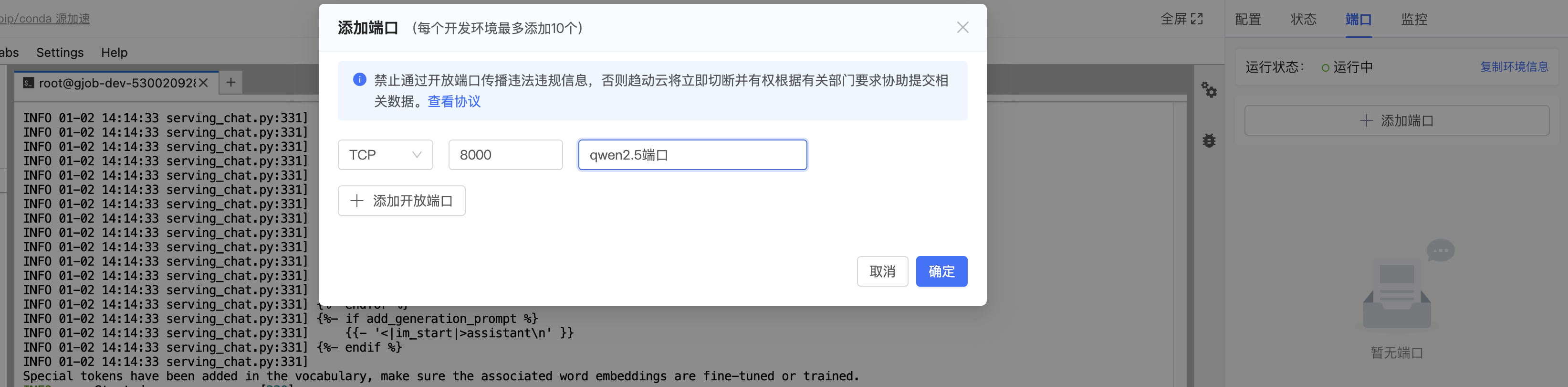
端口映射
在趋动云控制台的右侧"端口",添加端口映射如下:
调用验证
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://direct.virtaicloud.com:28462/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen2.5-0.5B-Instruct",
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "中华人民共和国的首都是哪里?"},
]
)
print("Chat response:", chat_response)
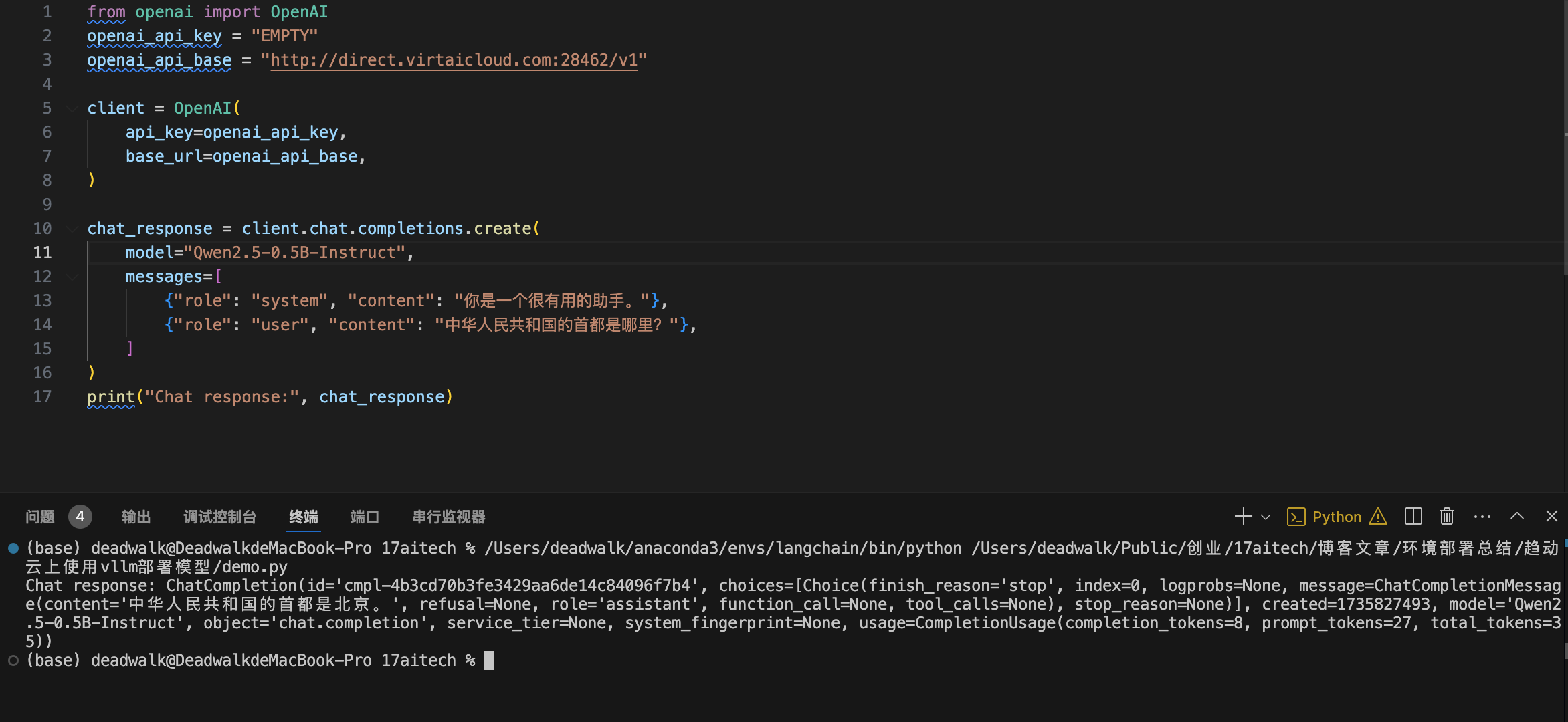
运行结果:
注意事项:
- 示例中,趋动云配置端口映射后的外部地址为:
direct.virtaicloud.com:28462,读者需要根据实际情况修改。 - 示例中,部署的模型为
Qwen2.5-0.5B-Instruct,请注意根据实际情况修改。 - 示例中,本地调用代码略过了
langchain库的安装,请记得安装。
部署embedding模型
vllm部署embedding模型存在诸多问题,如:vllm支持的embedding模型有限,vllm版本更新后支持的模型与官网不一致等等…
因此,embedding模型的部署还是建议通过xinference来进行,具体查看Xinference部署向量化模型
常见问题:
问题1:安装vllm时,报错ERROR: Could not install packages due to an OSError: [Errno 16] Device or resource busy: 'libnccl.so.2'
问题原因:该问题是因为安装vllm时,有程序占用了libnccl.so.2,导致安装失败。
解决方法:暂无好的解决方案,可以按照文章中的镜像,加载带有vllm的镜像。
问题2:启动vllm时,提示报错:OSError: We couldn't connect to 'https://huggingface.co' to load this file
问题原因:该问题一般是加载模型时,模型地址配置错误所致。
解决方法:检查--model 参数的模型地址是否正确,或者模型是否存在。




4人评论了“【模型部署】在趋动云上使用vllm部署模型”
raise RuntimeError(
RuntimeError: Engine process failed to start
添加新错误
再加个错误
Exception: data did not match any variant of untagged enum ModelWrapper at line 757443 column 3
换了N个镜像了 都不行
注意要使用带有vllm的镜像