
前言
在【模型训练】在AutoDl上使用LLamaFactory进行模型训练中,我们介绍了如何通过SSH建立隧道,进而访问LLamaFactory进行模型训练。本章,我们将介绍如何通过Xinference进行模型推理服务的部署。
环境准备
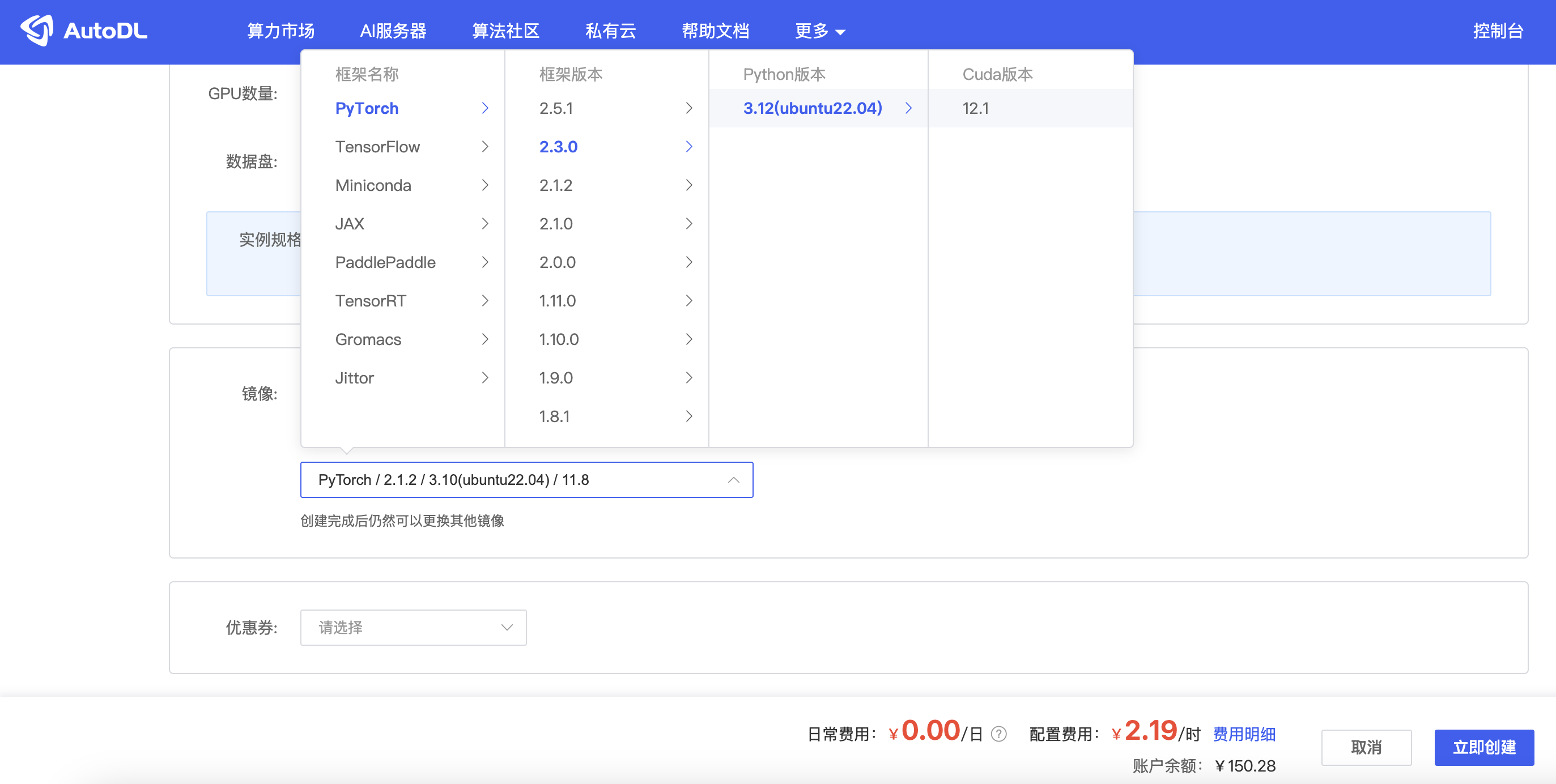
1.1 创建实例
根据以上的依赖环境版本,我们在AutoDL上选择较为稳定的Pytorch2.3.0+Python3.12+CUDA12.1。
1.2 安装Xinference以及引擎
# 安装 vllm 引擎
pip install "xinference[vllm]"
# 安装sentence-transformers
pip install sentence-transformers运行结果:

注意:
在实测过程中如果安装transformers引擎会失败,所以本例中改为使用vllm引擎。
1.3 端口映射(建立SSH隧道)
关于Mac和Wincows下建立SSH隧道的方法,在【模型训练】在AutoDl上使用LLamaFactory进行模型训练的端口映射章节有详细介绍,本章不再赘述。
-
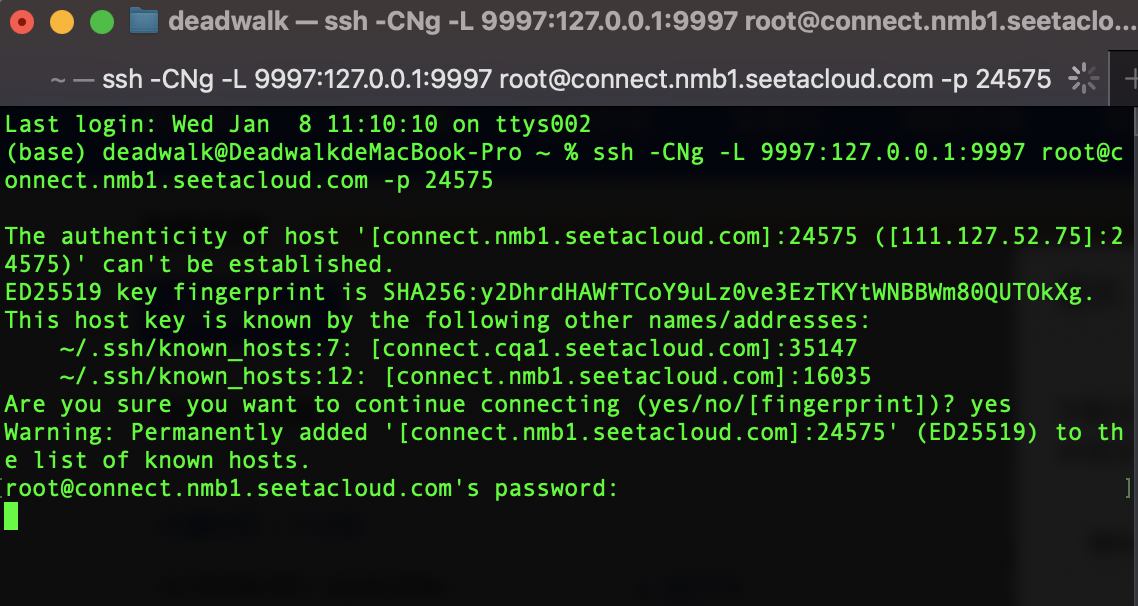
创建SSH命令
ssh -CNg -L 9997:127.0.0.1:9997 root@connect.nmb1.seetacloud.com -p 24575 -
运行SSH命令并输入密码
-
浏览器访问
http://localhost:9997,打开XInference的WebUI
模型部署
前置操作
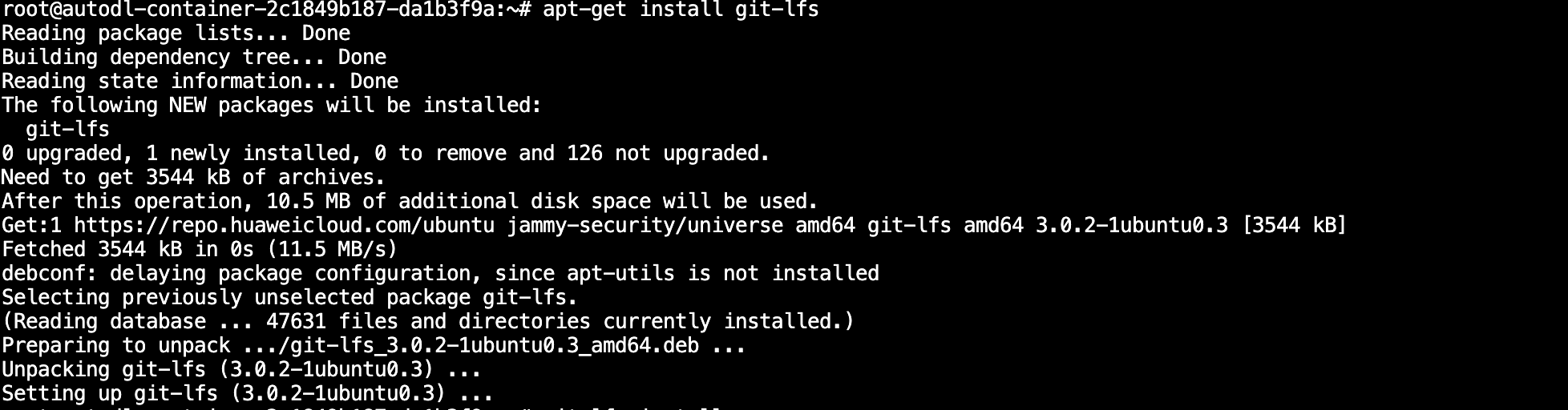
因为AutoDL镜像中默认没有安装Git-LFS,所以需要手动安装。
# 更新apt-get
apt-get update
# 安装git-lfs
apt-get install git-lfs运行结果:
1.1 部署chat模型
1.1.1 下载模型
我们配置一个chat模型,模型选择Qwen2.5-Instruct,模型路径选择Qwen2.5-0.5B-Instruct。
# 下载模型
git lfs install
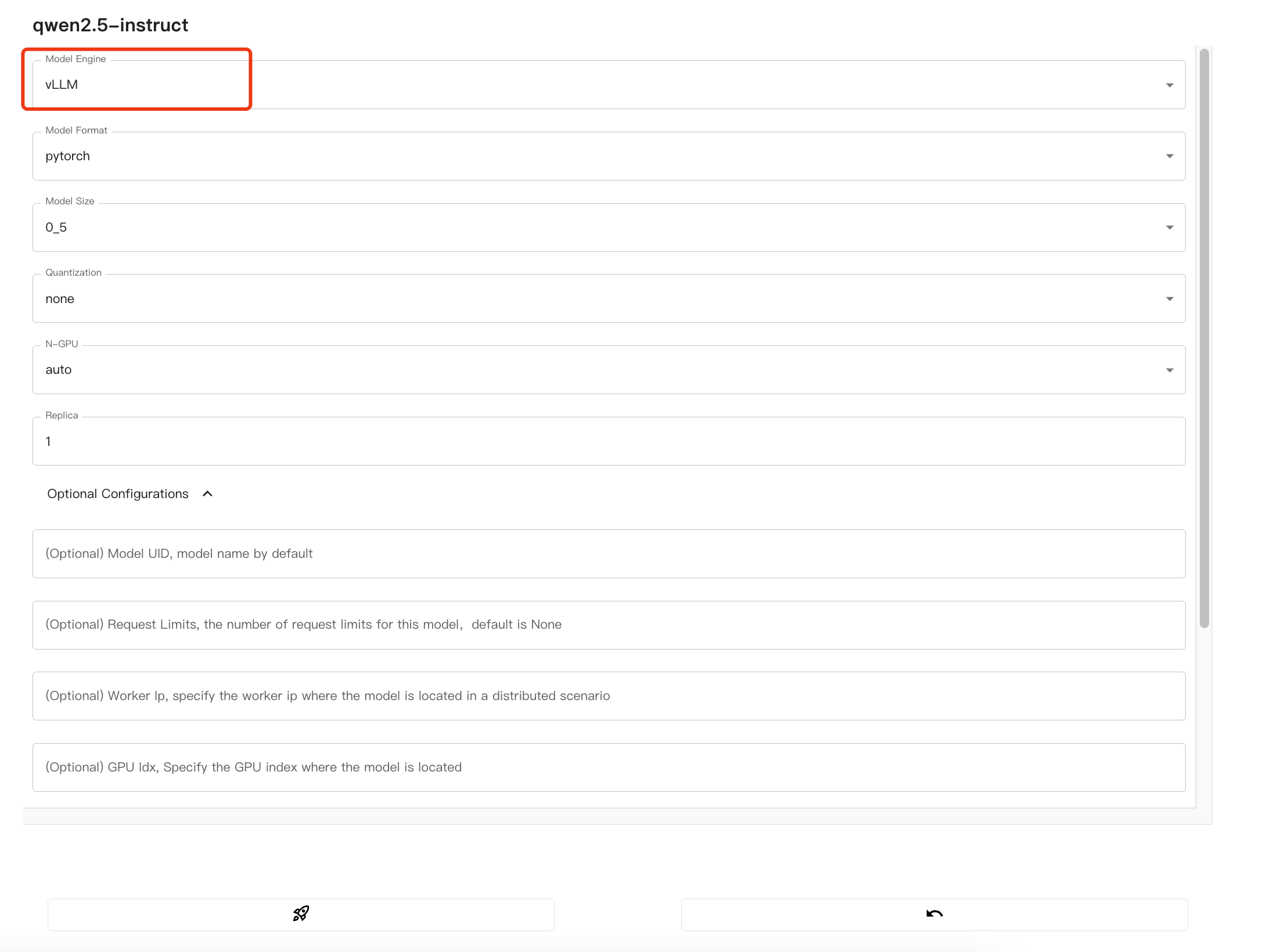
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git1.1.2 配置chat模型
在Xinference的WebUI中,配置chat模型:
注意:
因为我们在1.2安装Xinference以及引擎中安装的是vllm引擎,所以这里需要选择vllm。

配置完毕,之后启动模型即可。
1.1.3 测试chat模型
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:9997/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="qwen2.5-instruct",
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "中华人民共和国的首都是哪里?"},
]
)
print("Chat response:", chat_response)
运行结果:
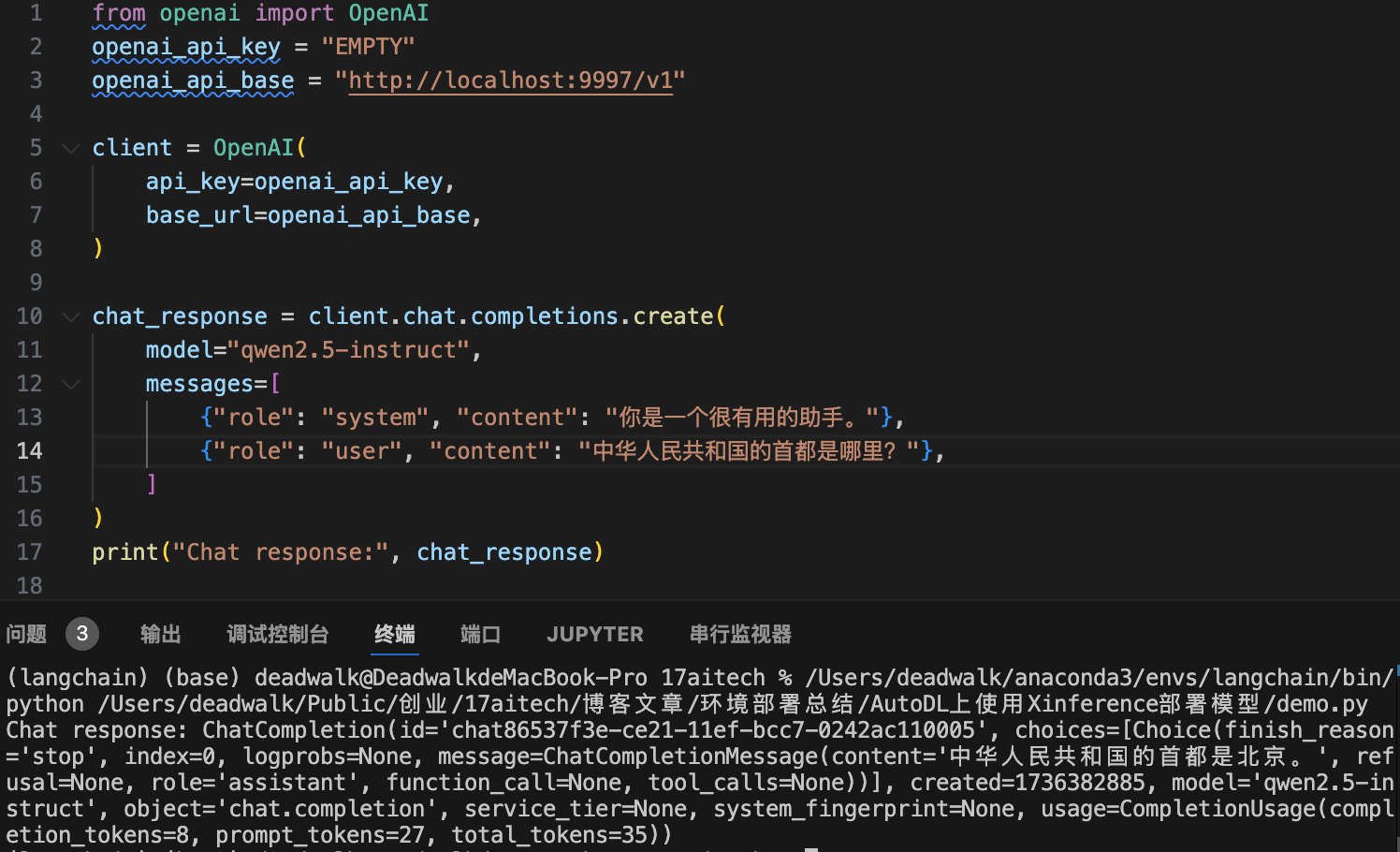
注意:
openai_api_base需要改为http://localhost:9997/v1,该地址是通过SSH与AutoDL实例建立的隧道连接,所以可以通过localhost访问实例。- SSH隧道需要在使用期间保持全程连接状态中,否则无法访问;如果模型需要给第三人使用,那么第三人也需要运行SSH命令建立隧道才可以使用。
model需要与Xinference中启动后的Model UID名称保持一致。
1.2 部署向量化模型
1.2.1 下载向量化模型
# 安装git-lfs
git lfs install
# 下载模型
git clone https://www.modelscope.cn/BAAI/bge-m3.git1.2.1 配置向量化模型
在Xinference的WebUI中,配置向量化模型:

配置完毕后,启动模型
1.2.3 测试向量化模型
from langchain_community.embeddings import XinferenceEmbeddings
server_url="http://localhost:9997/"
model_uid = "bge-m3"
embed = XinferenceEmbeddings(server_url=server_url, model_uid=model_uid)
embed.embed_query("你好")运行结果:
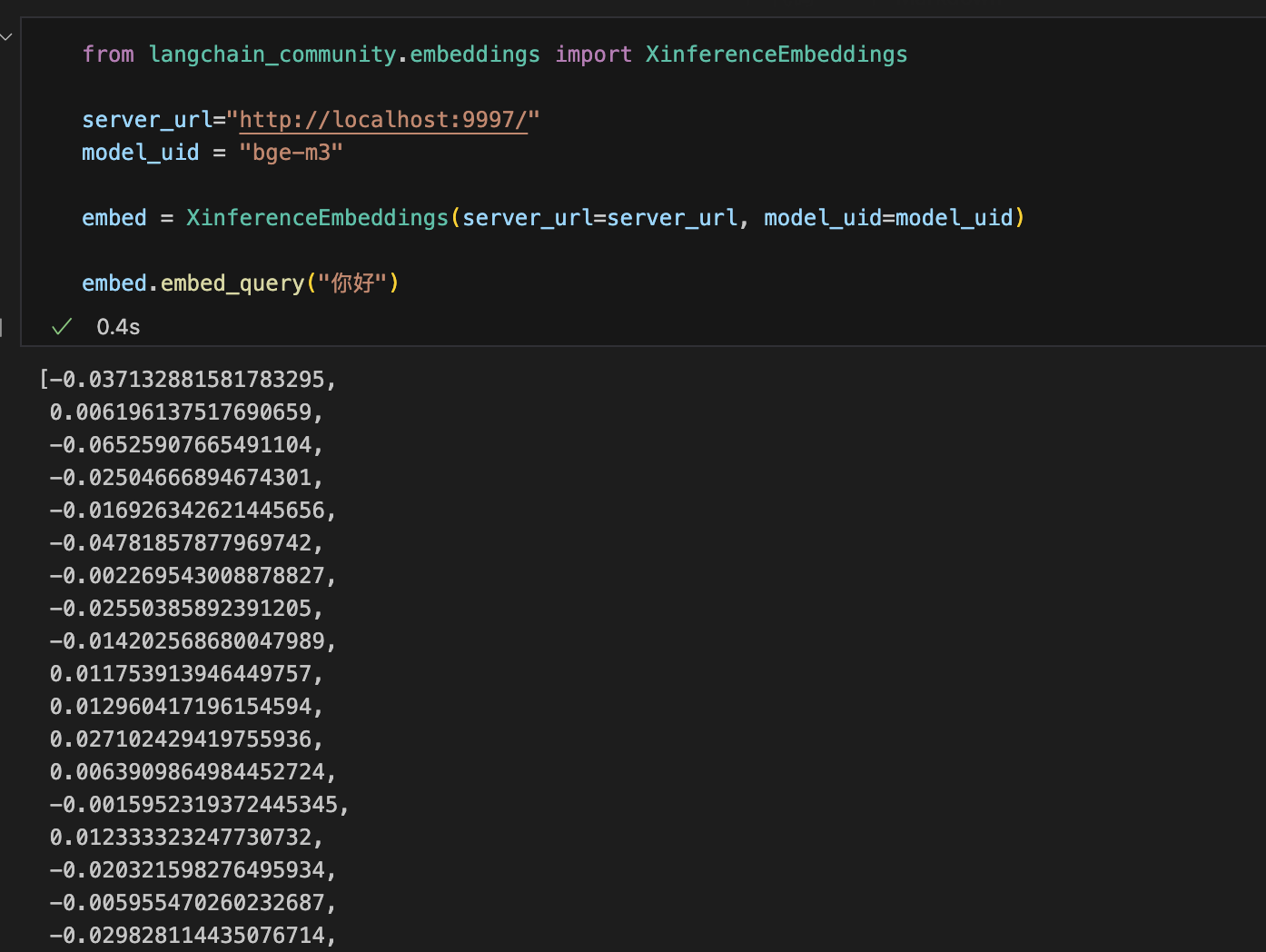
注意:
server_url需要改为http://localhost:9997/,同时要确保SSH隧道已经建立且全程保持连接。model_uid需要与Xinference中启动后的Model UID名称保持一致。
1.3 部署多模态模型
1.3.1 下载多模态模型
# 安装git-lfs
git lfs install
# 下载模型
git clone https://www.modelscope.cn/Qwen/Qwen2-VL-2B-Instruct.git1.3.2 配置多模态模型
在Xinference的WebUI中,配置多模态模型:
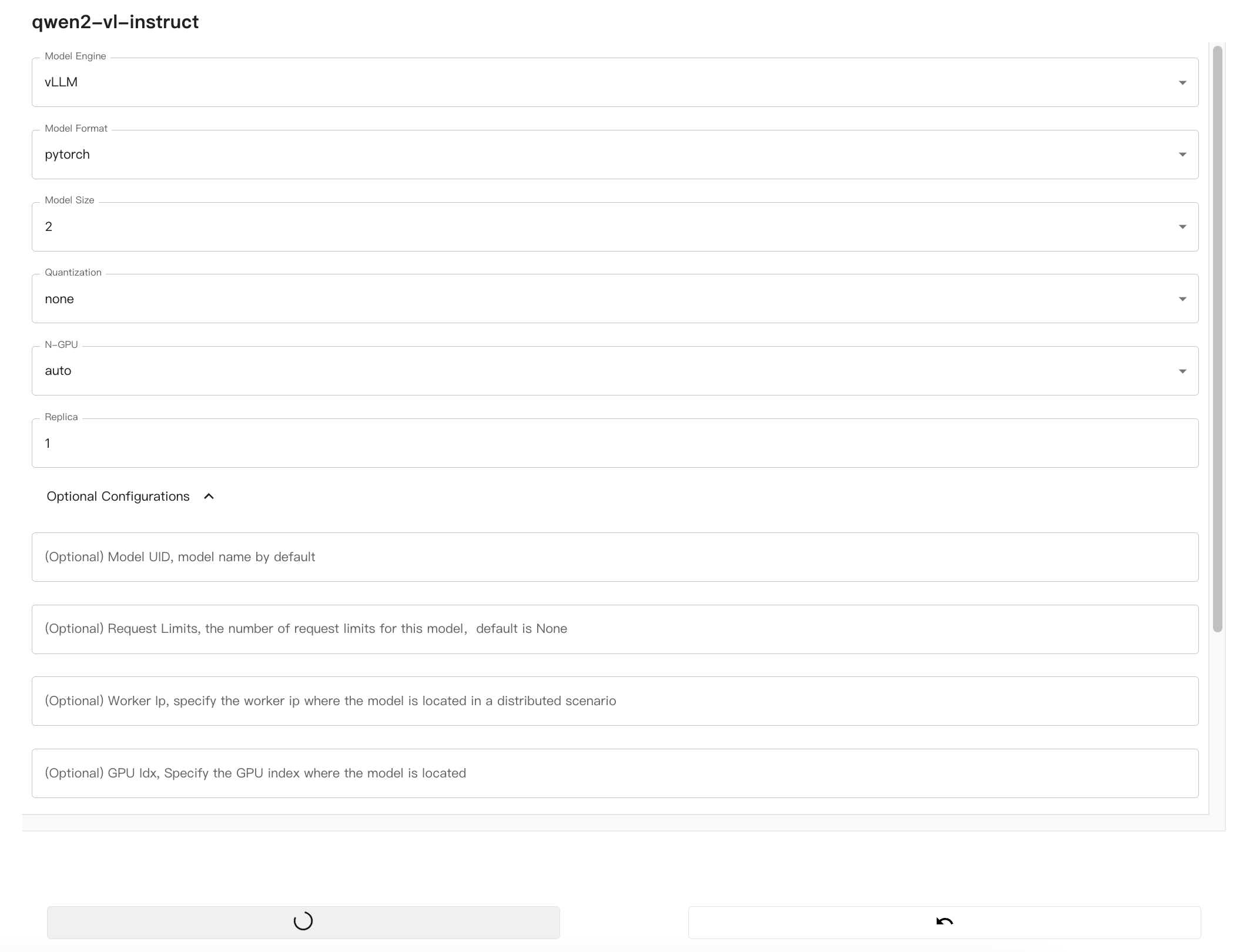
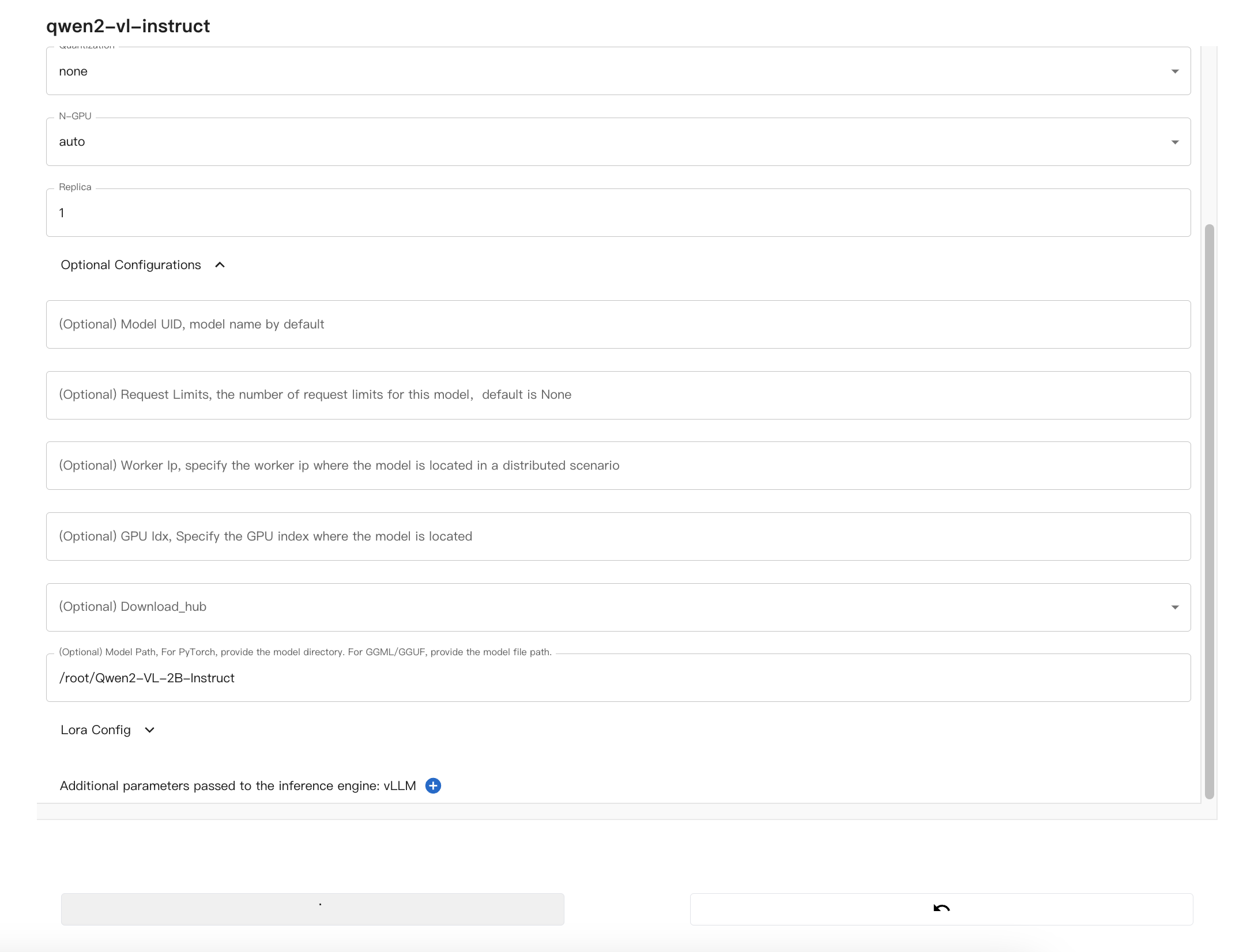
配置完毕后,启动模型

1.3.3 测试多模态模型
因为Qwen2-VL时会报没有安装qwen-vl-utils,所以需要手动安装。
pip install qwen-vl-utils使用下面代码调用模型:
from openai import OpenAI
import base64
# 配置OpenAI客户端
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:9997/v1" # 请根据实际端口映射地址修改
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
def encode_image_to_base64(image_path):
"""将图片转换为base64编码"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def chat_with_image(image_path, prompt):
"""与多模态模型对话"""
# 将图片转换为base64
base64_image = encode_image_to_base64(image_path)
messages=[
{
"role": "user",
"content": [
{"type":"text", "text":prompt},
{
"type":"image_url",
"image_url":{
"url":f"data:image/png;base64,{base64_image}"
}
}
]
}
]
# 调用模型
# try:
response = client.chat.completions.create(
model="qwen2-vl-instruct", # 使用部署的多模态模型名称
messages=messages,
max_tokens=1024,
temperature=0.7,
response_format={"type": "text"} # 指定响应格式为文本
)
return response.choices[0].message.content
# except Exception as e:
# return f"调用出错: {str(e)}"
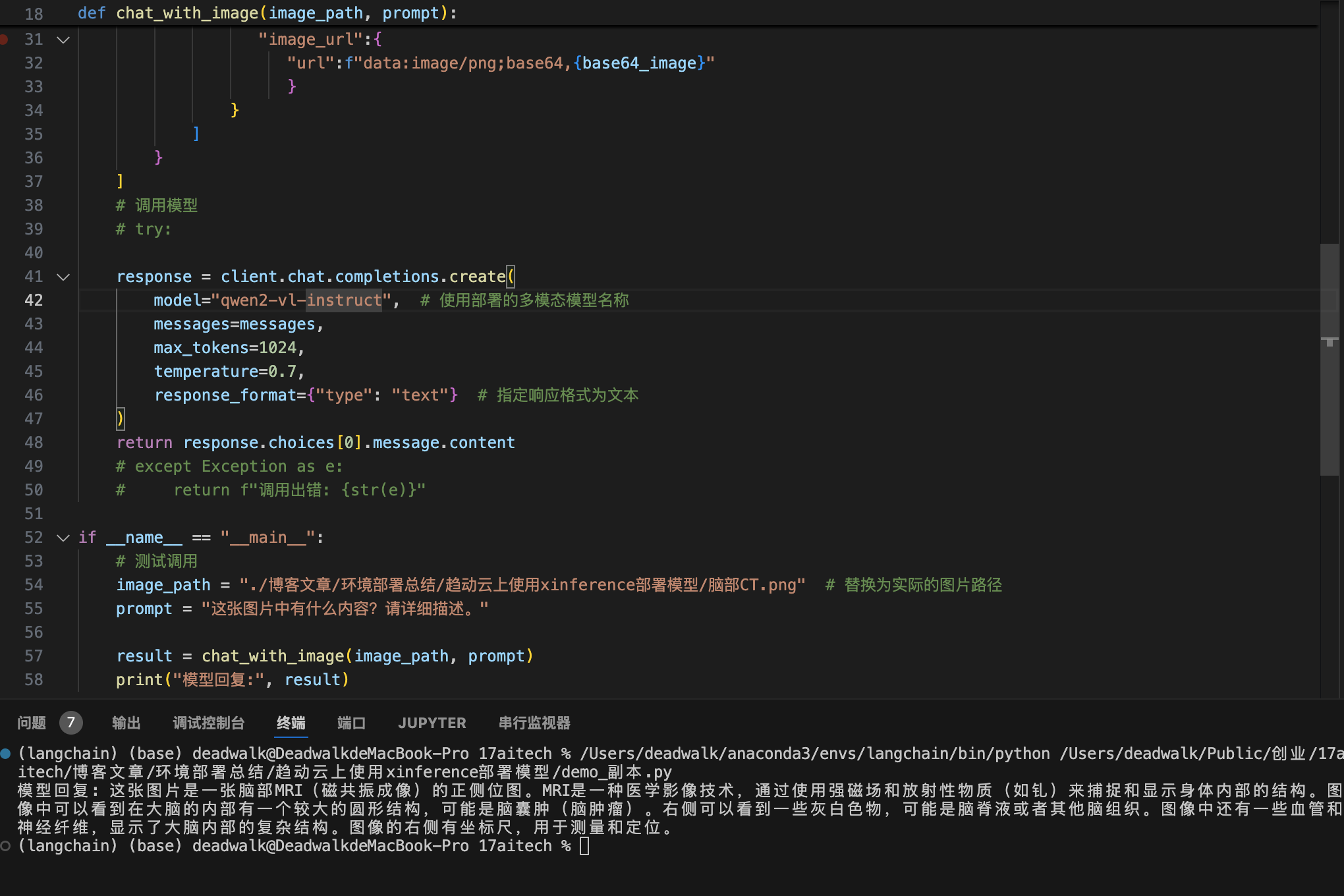
if __name__ == "__main__":
# 测试调用
image_path = "./脑部CT.png" # 替换为实际的图片路径
prompt = "这张图片中有什么内容?请详细描述。"
result = chat_with_image(image_path, prompt)
print("模型回复:", result) 运行结果:
总结
- AutoDL平台正常情况下,不对外提供Http或Https服务,所以需要通过SSH隧道建立连接。
- AutoDL平台安装
transformers引擎会失败,所以本例中改为使用vllm引擎。 - AutoDL平台默认没有安装Git-LFS,所以通过
apt-get install git-lfs手动安装。 - Chat模型、向量化模型、多模态模型部署成功之后,在远程调用时注意修改调用地址。
该系列文章
- 【模型部署】在AutoDL上使用Xinference部署模型
- 【模型训练】在AutoDL上使用LLamaFactory进行模型训练
- 【模型部署】在趋动云上使用xinference部署模型
- 【模型部署】在趋动云上使用vllm部署模型
欢迎关注公众号以获得最新的文章和新闻



