
前言
在机器学习章节【课程总结】Day6(上):机器学习项目实战–外卖点评情感分析预测中,我们曾借助sklearn进行了外卖点评的情感分析预测;接下来,我们将深入了解自然语言处理的基本概念、RNN模型以及借助RNN重新进行外卖点评的情感分析预测。
自然语言处理基本概念
正如机器学习中所学内容:数据集是汉字 ,机器无法处理(因为机器学习底层是对数字的处理),所以我们首先需要对数据数字化(也叫汉字向量化)。
因此,本章我们将重新学习汉字向量化的处理过程。
汉字向量化处理步骤
分词处理
第一步:使用jieba进行分词
import jieba
import torch
from torch import nn
s1 = '我吃饭了!'
s2 = '今天天气很好!'
s3 = '这辆车很好看!'# 使用jieba分词
jieba.lcut(s3)
# 输出结果
# ['这辆', '车', '很', '好看', '!']# 对s1~s3进行分词
words = {word for sentence in [s1, s2, s3] for word in jieba.lcut(sentence)}
# 输出结果为
# {'了', '今天天气', '吃饭', '好', '好看', '很', '我', '车', '这辆', '!'}
# 添加中间词
# <PAD>代表填充,用于补齐保持数据集长度一致
# <UNK>代表未知词
words.add("<PAD>")
words.add("<UNK>")
构建词典
第二步:构建词典
word2idx = {word: idx for idx, word in enumerate(words)}
idx2word = {idx: word for idx, word in enumerate(words)}
# word2idx内容为:
# {'很': 0,
# '今天天气': 1,
# '我': 2,
# '吃饭': 3,
# '<UNK>': 4,
# '!': 5,
# '<PAD>': 6,
# '好看': 7,
# '好': 8,
# '了': 9,
# '这辆': 10,
# '车': 11}
# idx2word内容为:
# {0: '很',
# 1: '今天天气',
# 2: '我',
# 3: '吃饭',
# 4: '<UNK>',
# 5: '!',
# 6: '<PAD>',
# 7: '好看',
# 8: '好',
# 9: '了',
# 10: '这辆',
# 11: '车'}数据对齐
第三步:将数据长度对齐
idx1 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s1)]
idx2 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s2)]
idx3 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s3)]
# 运行结果:
# [2, 3, 9, 5]
# [1, 0, 8, 5]
# [10, 11, 0, 7, 5]
# 可以看到s1,s2,s3长度不一致
# 补1个<PAD>,使得长度一致
idx1 = idx1 + [word2idx['<PAD>']]
idx2 = idx2 + [word2idx['<PAD>']]
# 补齐后结果:
# [2, 3, 9, 5, 6]
# [1, 0, 8, 5, 6]
# [10, 11, 0, 7, 5]
# 可以看到经过补<PAD>后,s1,s2,s3长度一致转张量
第四步:将数据转换为tensor张量
X = torch.tensor(data=[idx1, idx2, idx3], dtype=torch.long)
# 运行结果:
# tensor([[ 2, 3, 9, 5, 6],
# [ 1, 0, 8, 5, 6],
# [10, 11, 0, 7, 5]])
X.shape
# 输出结果:
# torch.Size([5, 3])知识点补充:
- 上述结构为
[seq_len, batch_size]
- seq_len:序列长度
- batch_size:批次大小
词向量处理
embedding概念
定义:“Embedding”(嵌入)是指将离散的对象(如单词、句子或其他类别)转换为连续的向量表示的过程。
nn.Embedding
nn.Embedding 是 PyTorch 中用于将离散的整数索引映射到连续的向量表示的一个重要模块。它通常用于自然语言处理(NLP)任务中,将词汇表中的每个单词(或符号)映射到一个固定大小的向量空间。
概念:nn.Embedding 是一个查找表,它将每个单词的索引映射到一个稠密的向量。这个向量可以被视为该单词的嵌入(embedding),它捕捉了单词之间的语义关系。
作用:
- 维度降低:将高维的稀疏数据(如独热编码)转换为低维的稠密向量,减少计算复杂度。
- 语义表示:嵌入向量可以捕捉单词之间的语义关系,例如“国王”和“王后”之间的关系。
- 训练灵活性:嵌入向量是可训练的参数,随着模型的训练,向量会根据上下文的不同而调整,从而更好地表示单词的含义。
nn.Embedding的使用
# num_embeddings:词汇表的大小,即可以嵌入的单词(或符号)的总数。
# embedding_dim:每个单词嵌入向量的维度,即降维之后的向量
# 过程:
# 1.先对单词进行One-hot编码,
# 2.然后乘以可学习的降维矩阵,进行线性降维,得到稠密矩阵
embed = nn.Embedding(num_embeddings=len(word2idx),
embedding_dim=6)
# [3, 5, 12] --> [3, 5, 6]
# [3, 5, 12]是降维矩阵,3代表有3句话,每句话5个单词,每个单词是12维的向量
# [3, 5, 6]是降维后的稠密矩阵,3代表有3句话,每句话5个单词,每个单词是6维的向量
embed(X)
# 输出结果:
# tensor([[[-0.4017, 1.0236, 2.2761, -0.7839, 0.7540, -0.2321],
# [-1.6476, -0.4885, 0.0074, 0.5844, 0.7727, -0.8194],
# [ 1.7552, -1.5381, -0.6061, 0.9384, 1.7029, -0.8575],
# [ 1.3455, -1.1269, -0.9036, 0.2579, 0.2227, -0.1865],
# [-1.5439, 0.7572, -0.1988, -1.4769, -1.1864, 0.9779]],
# [[ 0.2663, -0.2779, -0.3478, 0.2670, 0.6165, 1.1189],
# [ 0.8495, -1.6437, 0.4758, 1.7543, 1.3755, -0.3943],
# [-0.5781, 1.8609, -0.2794, 0.0876, 0.6801, -0.5056],
# [ 1.3455, -1.1269, -0.9036, 0.2579, 0.2227, -0.1865],
# [-1.5439, 0.7572, -0.1988, -1.4769, -1.1864, 0.9779]],
# [[ 1.3642, -2.9807, 0.6432, -0.3364, -0.5630, 2.3331],
# [-0.7616, 1.9371, 0.1402, 1.2046, 0.4930, 0.8405],
# [ 0.8495, -1.6437, 0.4758, 1.7543, 1.3755, -0.3943],
# [-0.4715, 1.9458, -0.9278, -0.7103, 0.0582, 0.6413],
# [ 1.3455, -1.1269, -0.9036, 0.2579, 0.2227, -0.1865]]],
# grad_fn=<EmbeddingBackward0>)
embed(X).shape
# 输出结果:
# torch.Size([3, 5, 6])
# 上述结构也表示为[N ,Seq_len, Embedding_dim]
知识点补充:
- NLP中的经典结构为
[N ,Seq_len, Embedding_dim]- CV中的经典结构为
[N, C, H, W]- 关于矩阵降维,可以查看【课程总结】Day5(下):PCA降维、SVD分解、聚类算法和集成学习进行回顾。
以上为自然语言处理基本概念,以及词向量处理。由于语言是具有时序性的,所以接下来将了解循环神经网络。
RNN循环神经网络
背景
一个例子:
“狗追猫。”
“猫追狗。”解释:在这两个句子中,单词的顺序是不同的,但它们的意思完全相反。第一个句子表示狗在追猫,而第二个句子则表示猫在追狗。这表明,单词的排列顺序(或时序)对于理解句子的含义至关重要。
在处理有时序性的语言时,模型通常使用以下方法:
- RNN(递归神经网络):通过循环结构来处理序列数据,能够记住之前的状态,从而捕捉时序关系。
- LSTM(长短期记忆网络) 和 GRU(门控循环单元):这些是 RNN 的变种,能够更好地处理长距离依赖关系。
RNN的简介
循环神经网络(Recurrent Neural Network,简称RNN)是一种能够处理序列数据的神经网络模型。循环神经网络属于深度学习神经网络(DNN),与传统的前馈神经网络不同,RNN在处理每个输入时都会保留一个隐藏状态,该隐藏状态会被传递到下一个时间步,以便模型能够记忆之前的信息。
RNN的结构
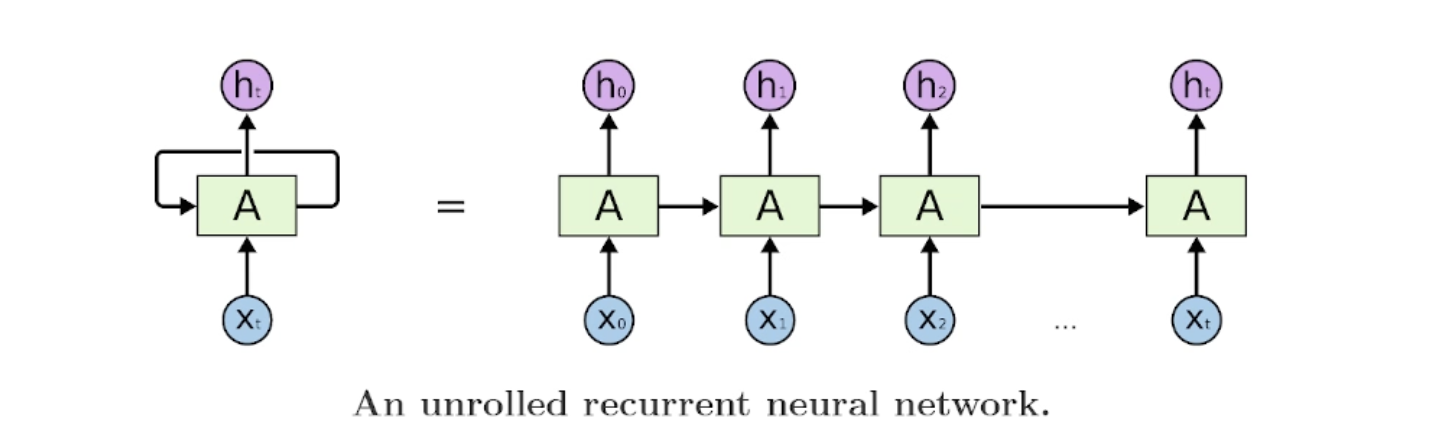
资料地址:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
图示说明:
X_t:当前时间步的输入向量。A:连接输入层和隐藏层的权重矩阵。h_t:当前时间步的隐状态,包含了序列的上下文信息。
例如:我吃饭了!
x_0= “我”,x_0输入到权重矩阵A得到h_0
x_1= "吃",x_1再输入到权重矩阵与上一步的h_0合并得到h_1
x_2= "饭",x_2再输入到权重矩阵与上一步的h_1合并得到h_2
…
最终得到h_n,h_n就是序列的上下文信息。
RNN的计算公式
h_t = \tanh(x_t W_{ih}^T + b_{ih} + h_{t-1} W_{hh}^T + b_{hh}) h_t:在时间步t的隐状态,表示当前时间步的记忆。x_t:在时间步t的输入向量,表示当前输入。W_{ih}:输入到隐状态的权重矩阵,用于将当前输入x_t转换为隐状态的输入部分。W_{hh}:隐状态到隐状态的权重矩阵,用于将前一时间步的隐状态h_{t-1}传递到当前时间步。b_{ih}和b_{hh}:分别是输入和隐状态的偏置项。\tanh:激活函数,通常用于引入非线性特性,使模型能够学习复杂的模式。
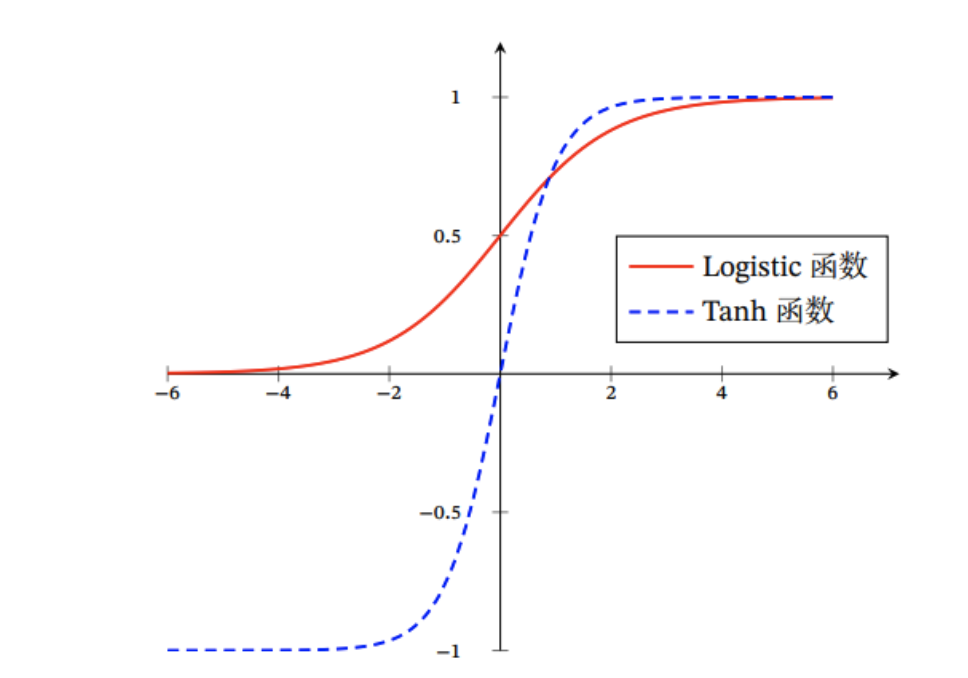
知识点补充:
激活函数使用了Tanh函数而不使用Sigmoid函数的原因是:
- Sigmoid的导数范围在[0,0.25]之内;
- Tanh的导数范围在(0,1];
- RNN需要不断的循环,导数值小的更容易导致梯度消失。
RNN的API使用
自动循环
# 自动循环:
# 创建RNN模型
rnn = nn.RNN(input_size=6,
hidden_size=7,
batch_first=True)
# 接着之前的例子
X1 = embed(X)
out, hn = rnn(X1)
out.shape, hn.shape
# 输出结果:
# torch.Size([3, 5, 7])
# torch.Size([1, 3, 7])
# out.shape:每一步的输出
# hn.shape:最后一步的输出手写循环
# 手动循环:
# 创建RNN模型
rnn_cell = nn.RNNCell(input_size=128,
hidden_size=256)
X = torch.randn(13, 2, 128)
X.shape
# 输出结果:
# torch.Size([13, 2, 128])
"""
手写循环实现RNN
"""
h0 = torch.zeros(2, 256, dtype=torch.float32)
out = []
for x in X:
h0 = rnn_cell(x, h0)
out.append(h0)
out = torch.stack(out)
len(out), out.shape
# 输出结果:
# (13, torch.Size([13, 2, 256]))项目:外卖点评情感分析预测(使用RNN)
(待补充)
内容小结
- NLP自然语言处理
- 数据对齐:在数据对齐时,可以通过添加\<PAD>补齐长度
“Embedding”(嵌入)是指将离散的对象(如单词、句子或其他类别)转换为连续的向量表示的过程。- torch中使用
nn.Embedding进行嵌入操作。 - Embedding的过程是:先对单词进行One-hot编码,然后乘以可学习的降维矩阵,进行线性降维,得到稠密矩阵
- NLP中的经典结构为
[N ,Seq_len, Embedding_dim]
- RNN循环神经网络
- RNN通过循环结构来处理序列数据,能够记住之前的状态,从而捕捉时序关系。
- RNN在处理每个输入时都会保留一个隐藏状态,该隐藏状态会被传递到下一个时间步,以便模型能够记忆之前的信息
- 使用RNN模型时,可以通过
nn.RNN创建模型,out.shape对应是每一步的输出,hn.shape对应是最后一步的输出 - RNN的计算公式中,激活函数使用了Tanh函数的原因是:RNN需要不断的循环,导数值小的更容易导致梯度消失。
参考资料
欢迎关注公众号以获得最新的文章和新闻




1人评论了“【课程总结】Day17(上):NLP自然语言处理及RNN网络”
tensor([[ 2, 3, 9, 5, 6], [ 1, 0, 8, 5, 6], [10, 11, 0, 7, 5]]) torch.Size([3, 5])