
背景
随着深度学习框架应用(如YOLO)以及大模型的微调,租用GPU云环境是一种低成本、灵活性高的方案。本章将介绍众多云服务商中的两个选择:阿里云和趋动云。
模型训练的环境
从软硬件维度来看,训练模型一般需要准备的内容如下:
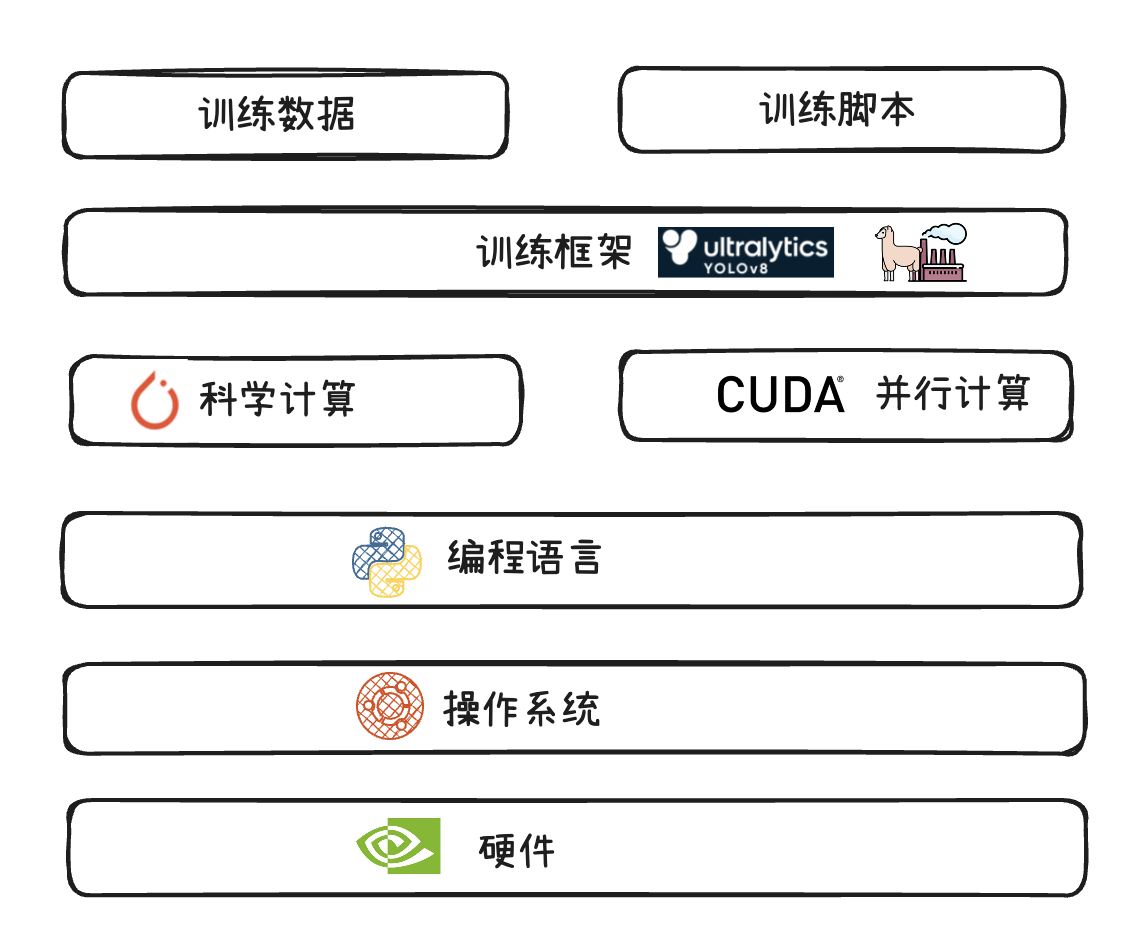
- 硬件:一般需要高性能的GPU显卡,目前主流的有:RTX 4090D、A100等等
- 操作系统:目前较为主流的是使用
Ubuntu系统。 - 编程语言:目前主流是使用
Python。 - 科学计算:目前主流是使用
PyTorch。 - 并行计算:搭配Nvidia显卡使用的并行计算平台是
CUDA。 - 训练框架:根据训练的任务而选择,目标检测类的主要是
YOLO,大模型方向有LLamaFactory等。
环境准备的痛点
通过上述的罗列,我们可以看到进行深度学习的环境准备还是比较多的问题:
- 成本问题:购买高性能显卡,成本高且利用率不高。
- 维护问题:无论是从硬件机器的维护,还是到软件环境的构建和维护,都会花费不少的时间成本。
- 容量问题:对于大的模型,普通的家用4090D显卡,受限于显卡容量,无法满足。
痛点解决方案
针对以上的痛点问题,租用GPU云环境是一种低成本、灵活性高的方案。它具有的特点:
- 成本低:通过租用GPU云环境,可以做到按使用量付费,不使用就关闭环境,避免了购买机器的费用以及折旧费用。
- 维护简单:GPU云环境一般都预置了适用于训练的环境,例如:Ubuntu、Python、PyTorch、CUDA等,用户只需关注自己任务的训练即可。
- 灵活度高:对于显存要求高的场景,可以灵活地扩展GPU显存,以满足需求。
GPU云环境方案对比
| 特性 | 阿里云 | 趋动云 |
|---|---|---|
| 价格 | 14元/小时(最低配置) | 0.99元/小时(学习使用的medium配置) |
| 优惠策略 | 新用户100小时免费GPU算力 限时3个月的5000算力资源 | 新用户注册赠送70算力时 |
| 便捷性 | 支持root命令,拉取外部数据和代码方便,扩展性高 | 提供了丰富的交于UI, 端口对外映射方便,支持离线训练 |
| 不足 | 服务器关闭后,数据无法持久化存储(关联阿里云账号并授权后,可以持久化保存) | 模型和数据需要按照官方提供的方法上传,root、docker等命令没有权限使用,灵活性较不足 |
阿里云使用方法
注册账号
- 访问http://modelscope.cn/, 按照提示,完成魔搭社区账号的注册。
- 访问https://www.aliyun.com/, 按照提示,完成阿里云账号的注册。
领取优惠券
目前阿里云有两个优惠可以领取:
- 优惠一:在魔搭社区绑定阿里云,可以获得100小时免费GPU算力。
- 优惠二:在阿里云官网领取新手保护期的5000算力。
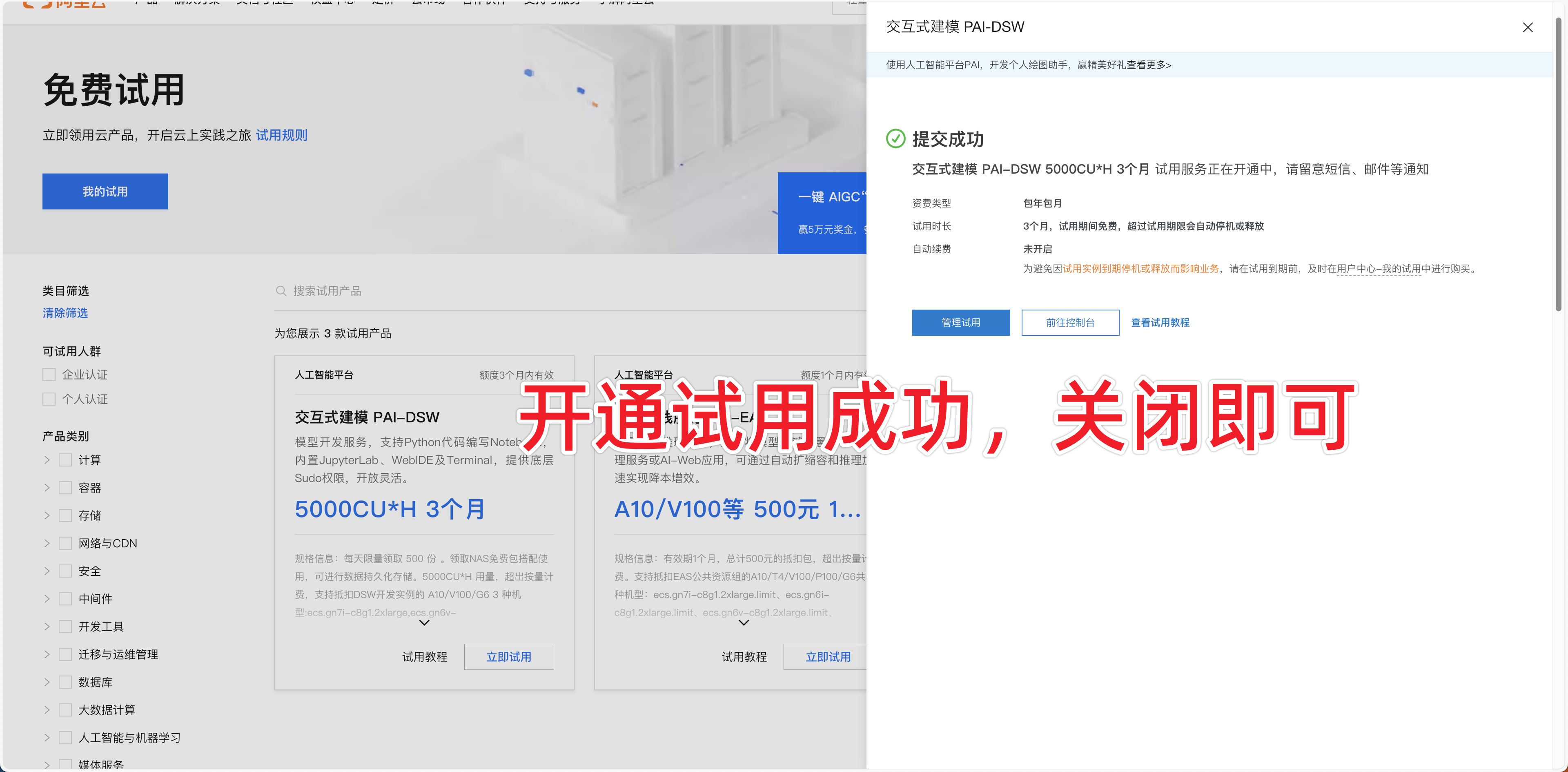
优惠一领取方法:登录魔塔社区后,按照如下提示操作,领取优惠。
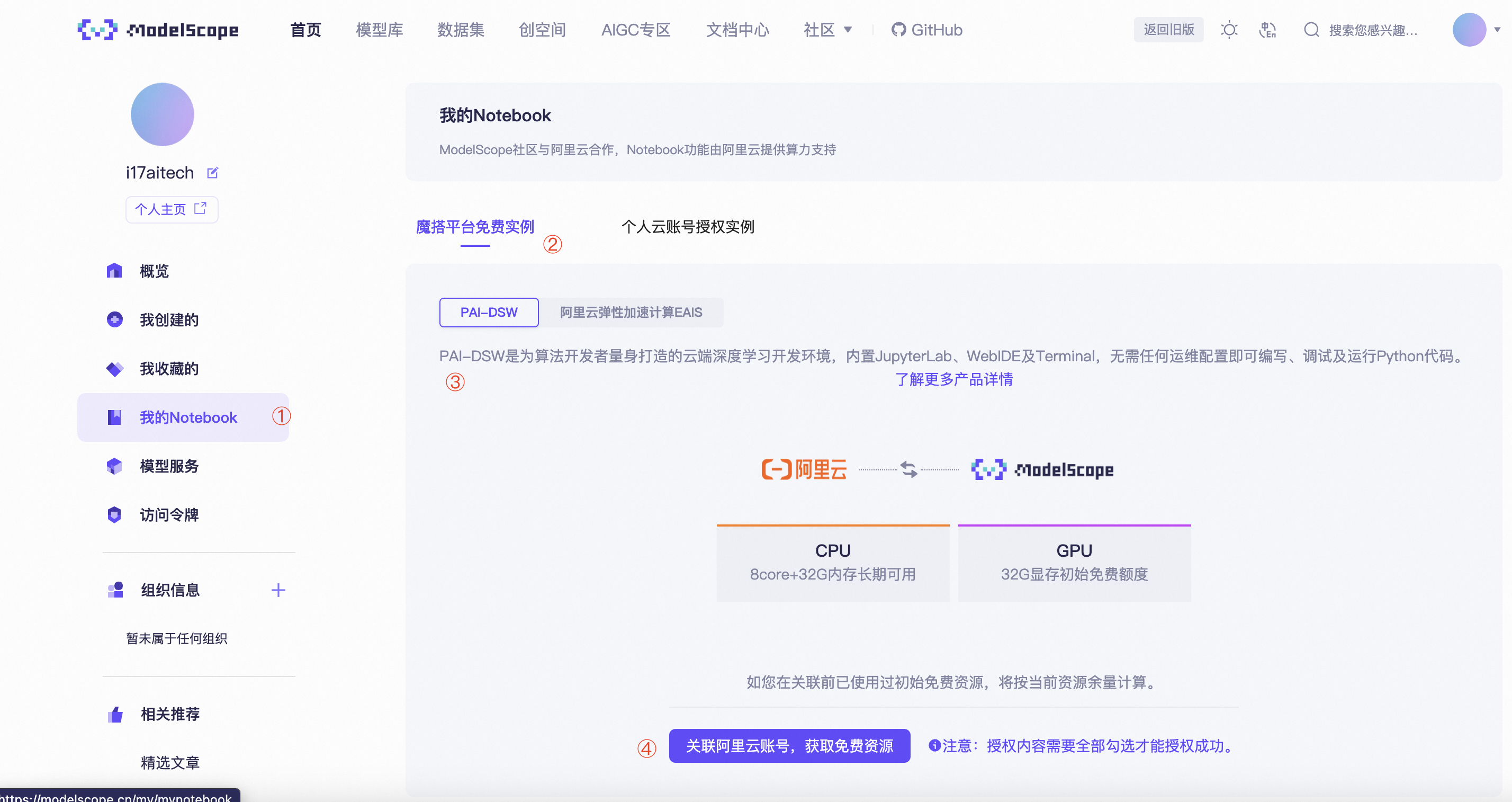
领取成功之后
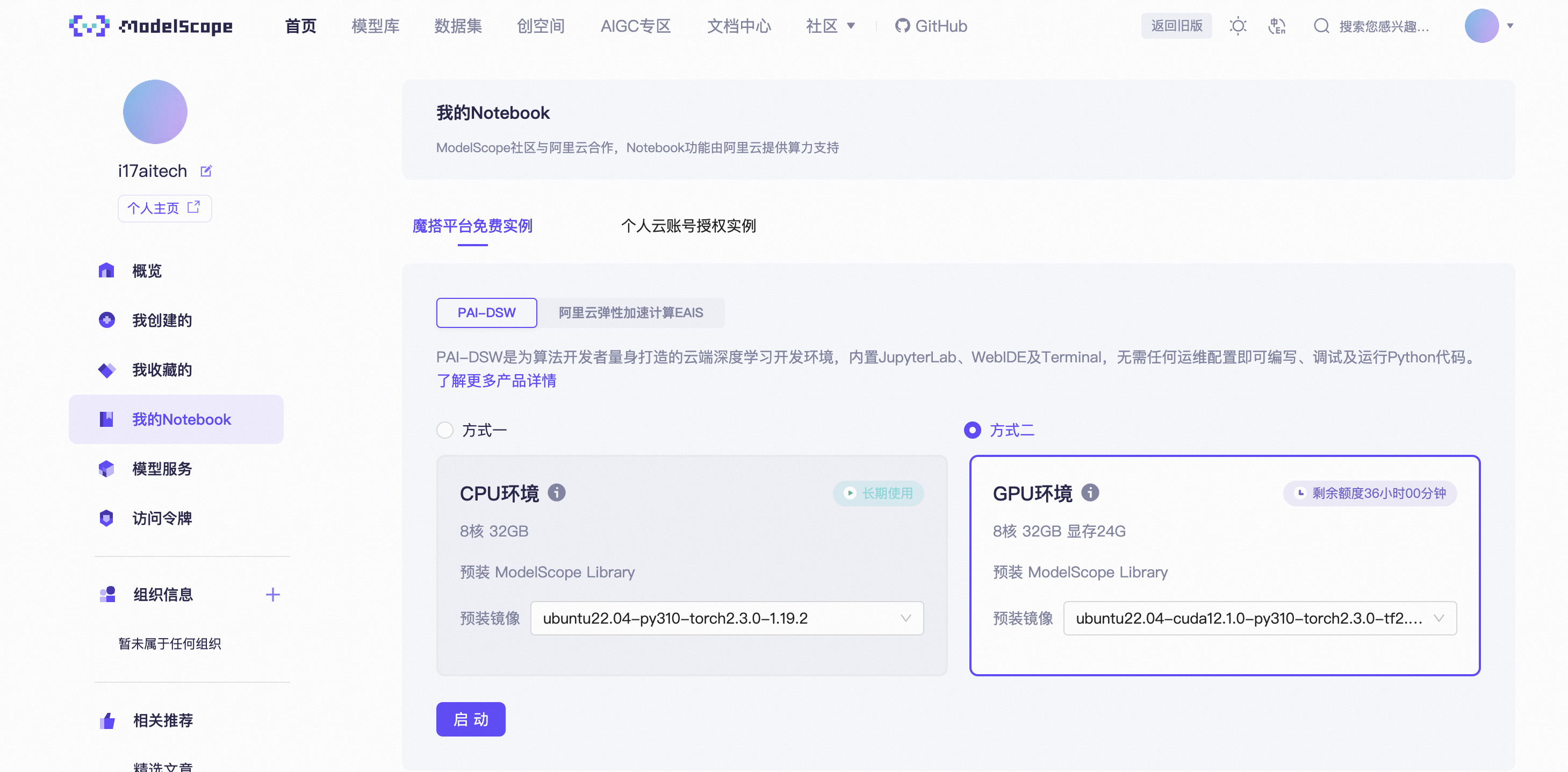
优惠二领取方法:
- 访问https://free.aliyun.com/
- 筛选
人工智能与机器学习,按照如下图示领取优惠。
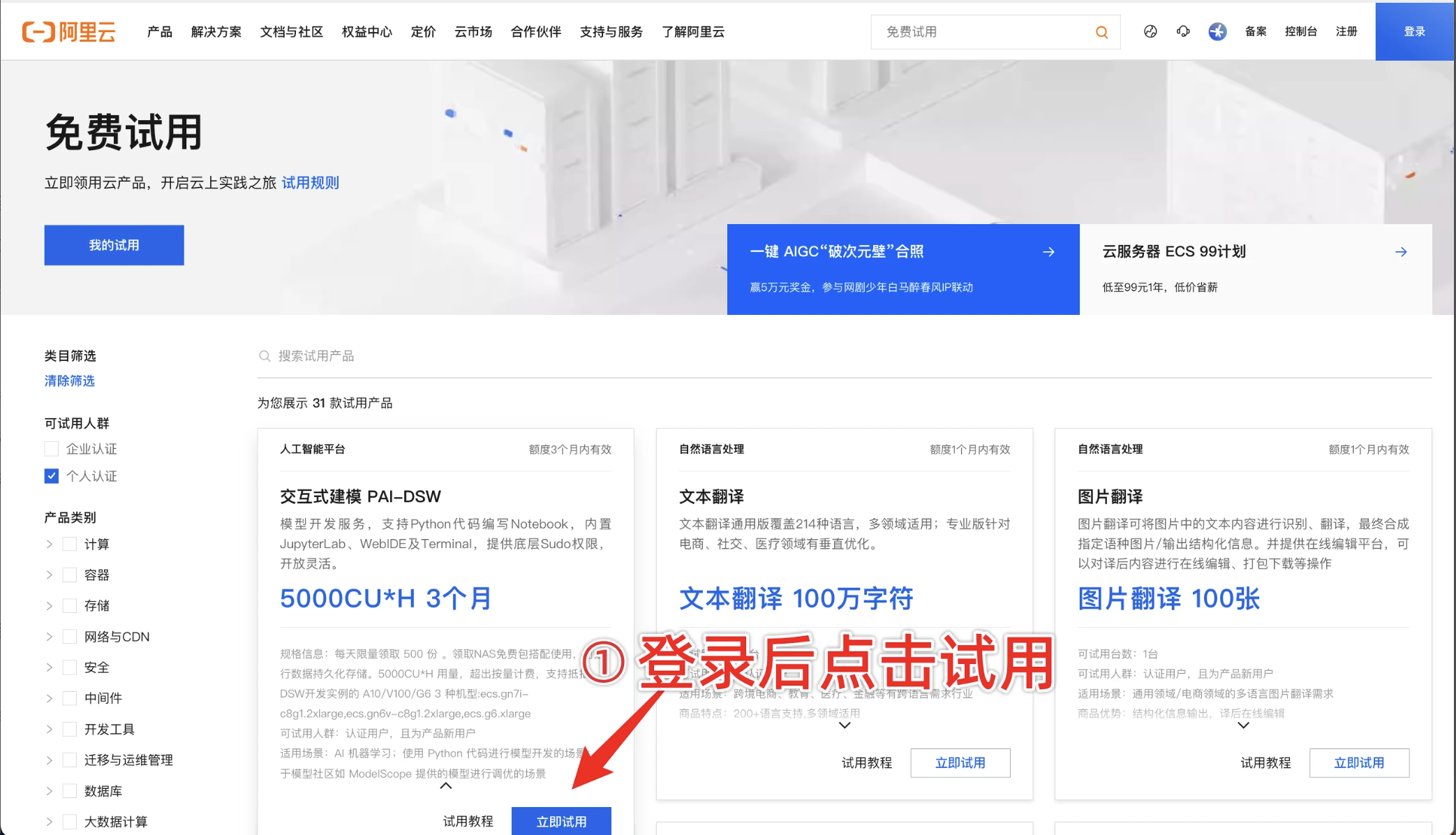
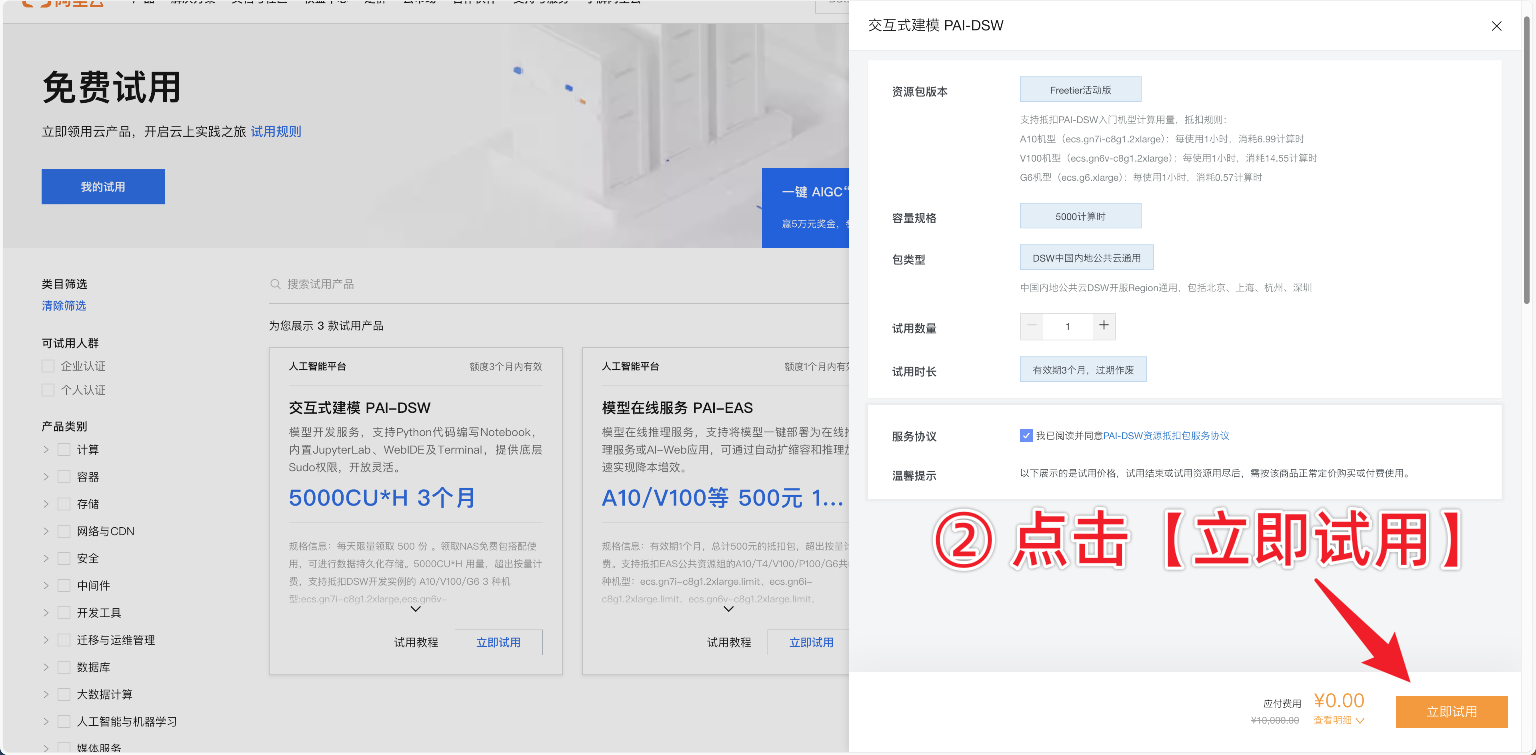
以上两个优惠不冲突,可以叠加使用。
使用方法
登录服务
- 登录魔搭社区,切换至我的Notebook→选择PAI-DSW服务→GPU环境→启动。

检查环境
因为GPU云服务器已经预装了ubuntu、Python、PyTorch等,所以我们只需要简单检查一下环境即可。
# 检查python版本
python --version
# 检查cuda版本
nvcc --version准备训练框架
我们以YOLO为例,进行训练框架的准备工作。
# 参考YOLO官网的说明方式安装
# 直接使用pip安装ultralytics
pip install ultralytics
安装完毕
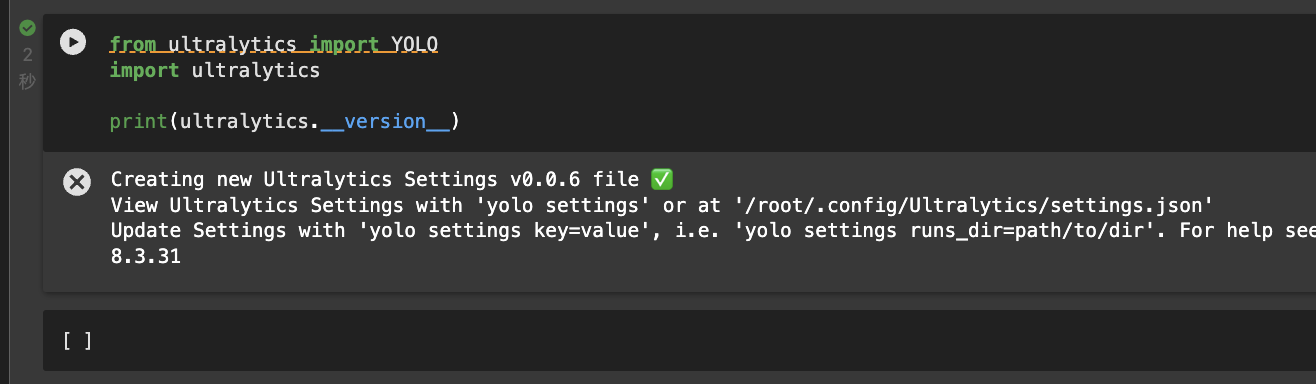
新建一个notebook,验证YOLO安装成功
from ultralytics import YOLO
import ultralytics
print(ultralytics.__version__)运行结果:
准备训练数据
点击上传按钮
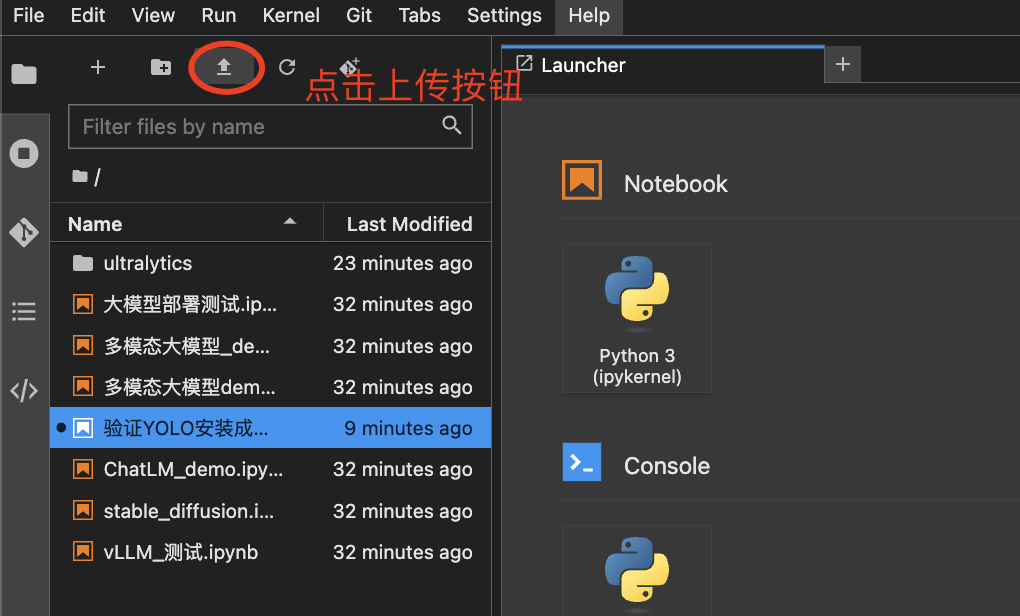
文件上传完毕后,使用unzip命令解压训练数据
unzip gestures.zip准备训练脚本
新建notebook后,准备训练脚本并配置训练数据data的目录
from ultralytics import YOLO
# 1,构建模型
model = YOLO("yolov8n-cls.yaml")
if __name__ == "__main__":
# 2,训练模型
results = model.train(data="/mnt/workspace/gestures",
epochs=100,
imgsz=128,
batch=8
)data对应训练数据的保存路径,可以通过
pwd命令查看。
开始训练
配置相应的训练参数后,运行训练代码,即可开始训练。
- epochs: 训练轮数
- imgsz: 图像尺寸
- batch: 批次大小
注意:batch的大小设置与显存占用有关,如果设置太大的话,意味着一个批次数据量过多,显存容纳不下可能会异常;如果设置太小的花,意味着显存的利用率不够。

完成训练
训练完毕后,会在训练脚本同一目录下生成runs目录,里面包含训练的日志,以及训练的模型。
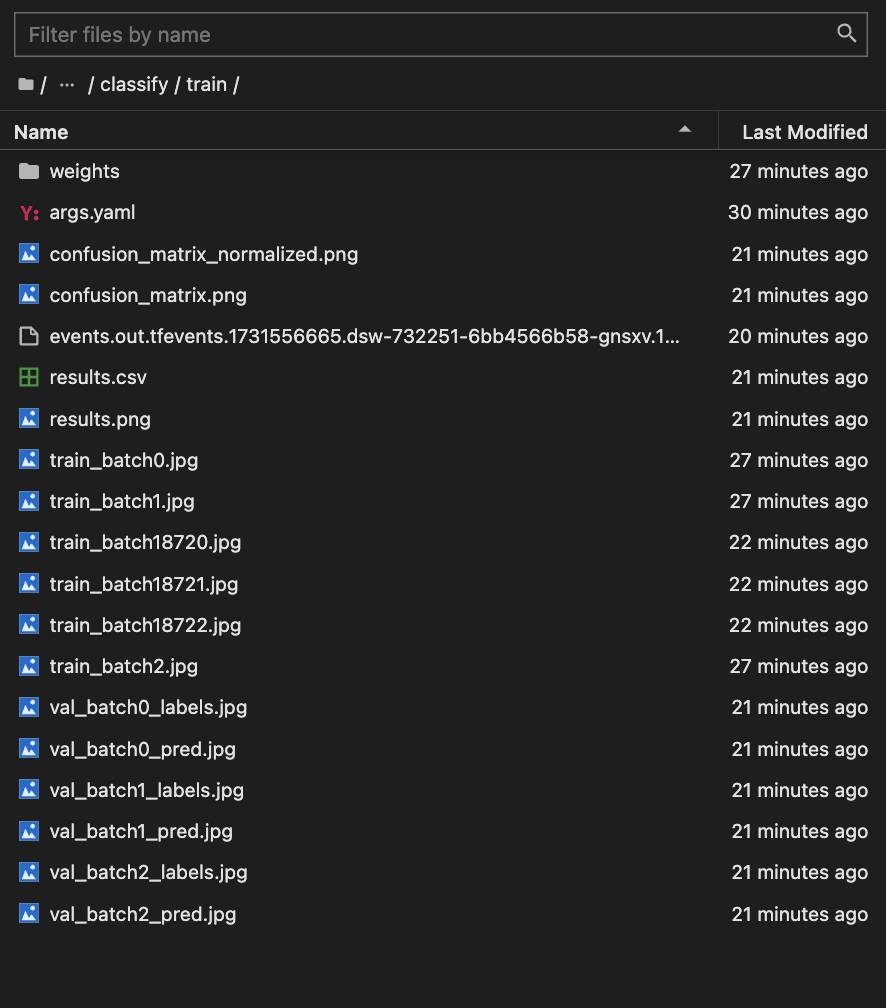
接下来,就可以使用weights目录下的best.pt进行预测,这部分内容不再赘述,具体可以参考【课程总结】Day11(下):YOLO的入门使用中关于手势识别的部分。
注意事项
- 阿里云默认情况下,关闭云服务器是不会保留数据和环境(所谓环境就是指安装的组件依赖)。
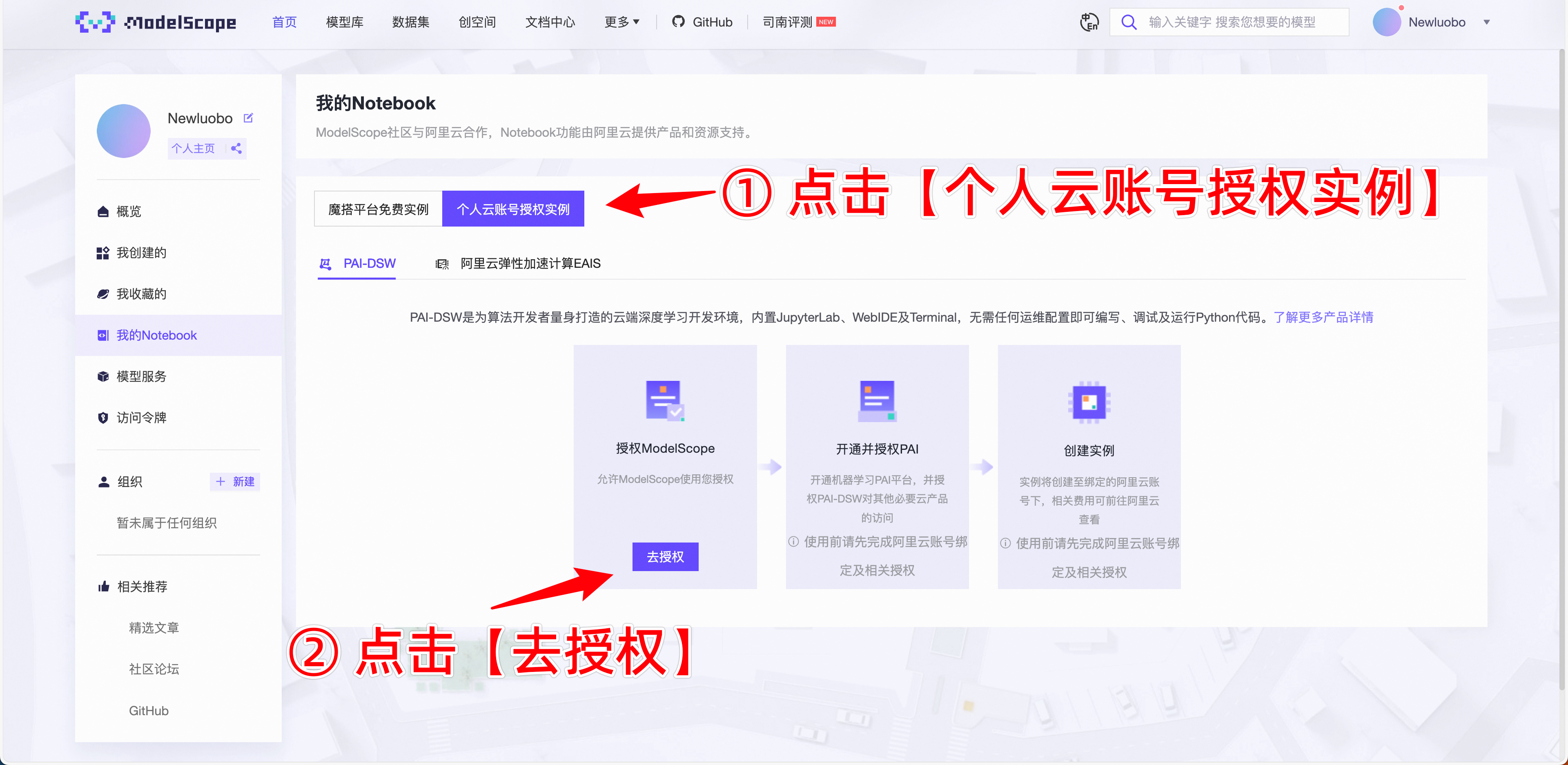
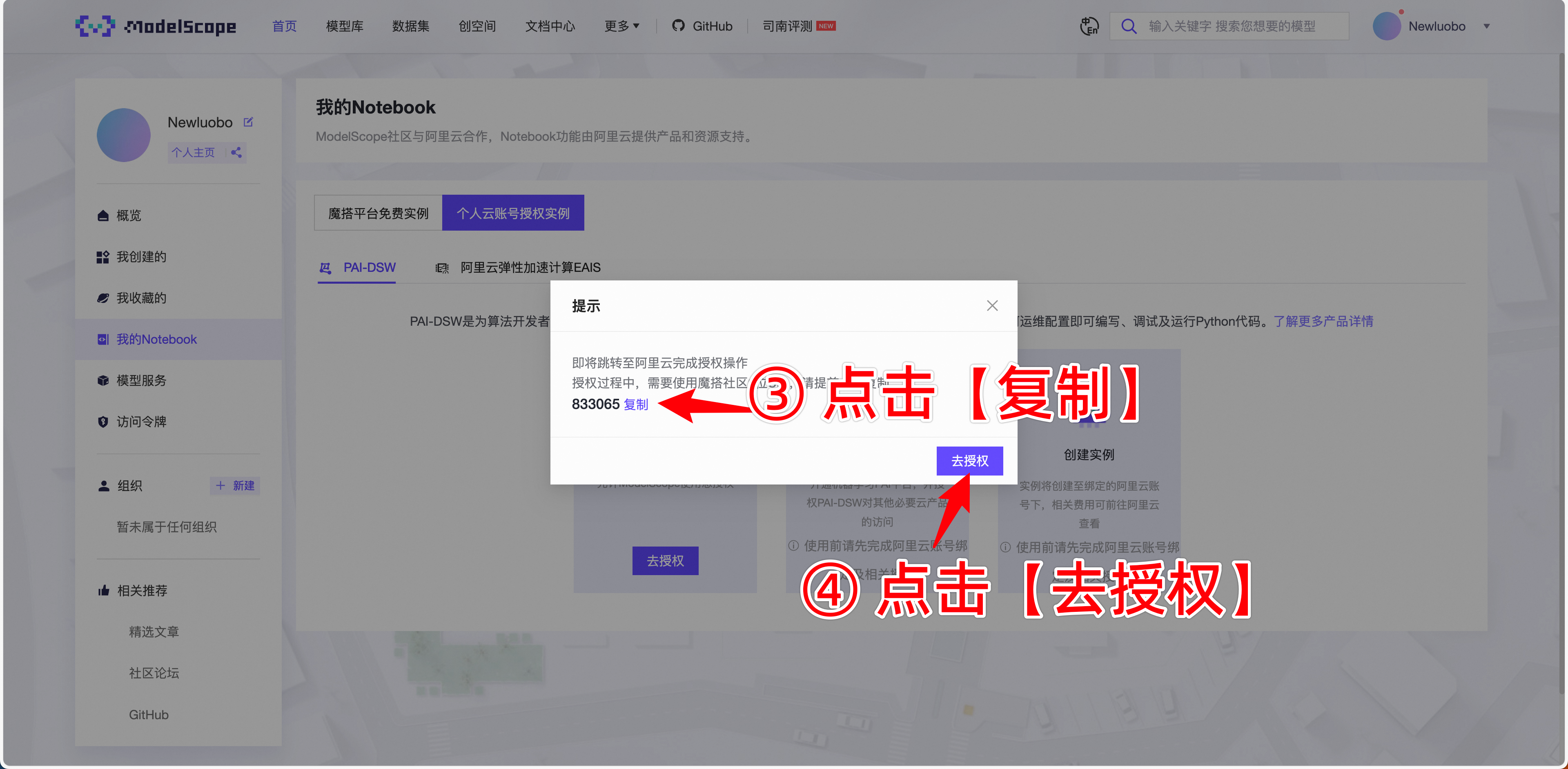
- 如果需要保留数据,则需要在魔搭社区上选择 个人云账号授权,具体方法如下:
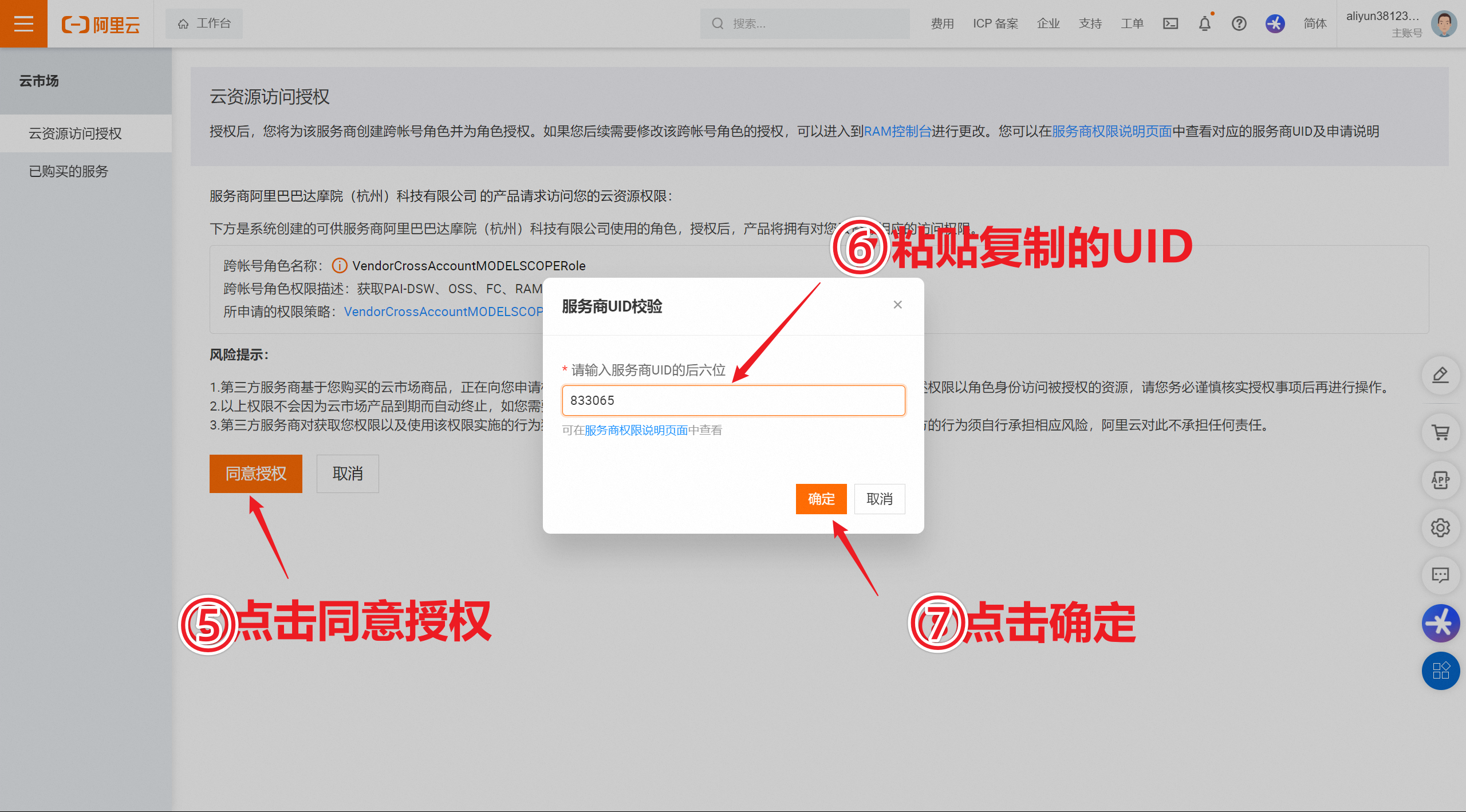
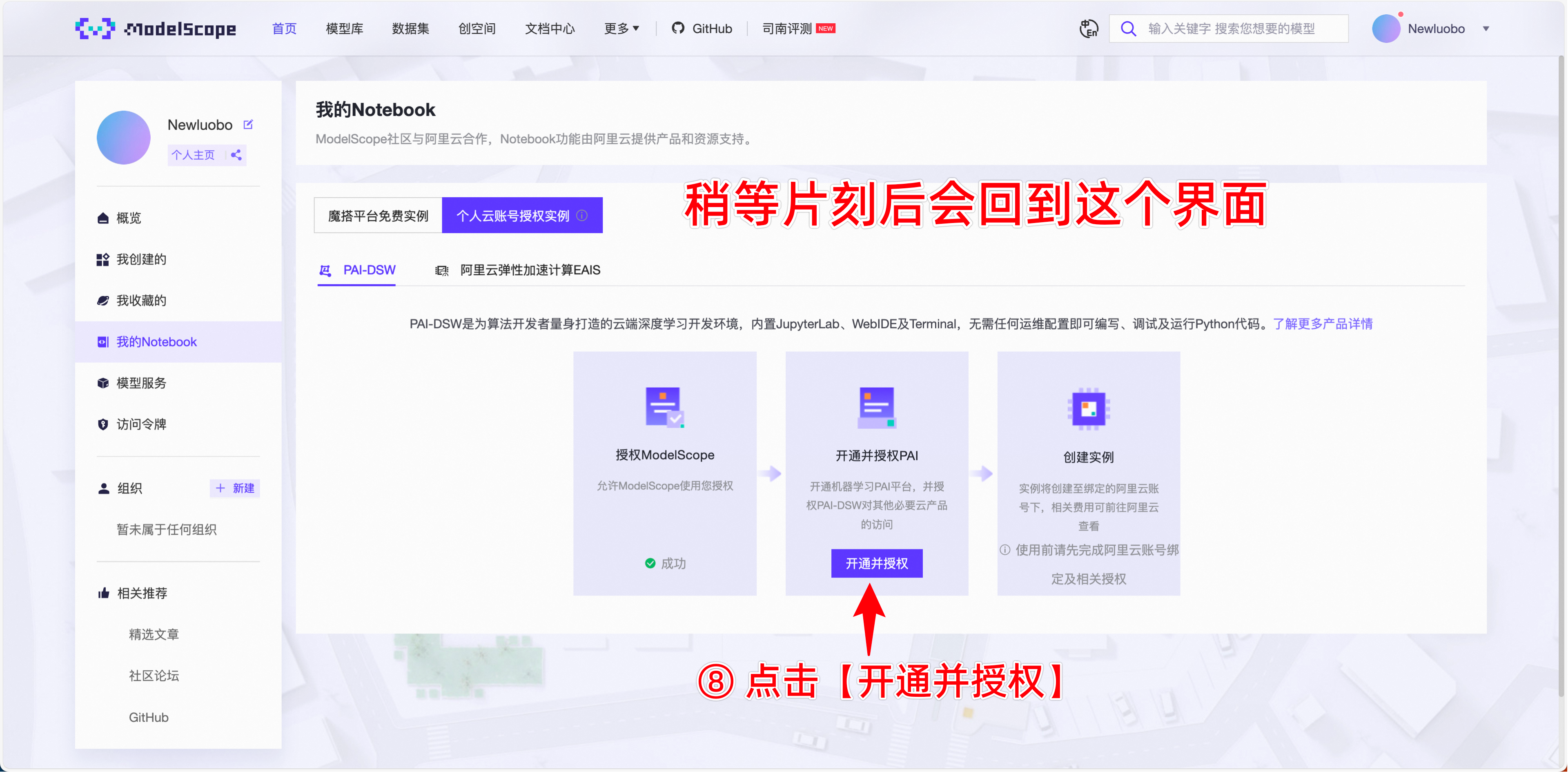
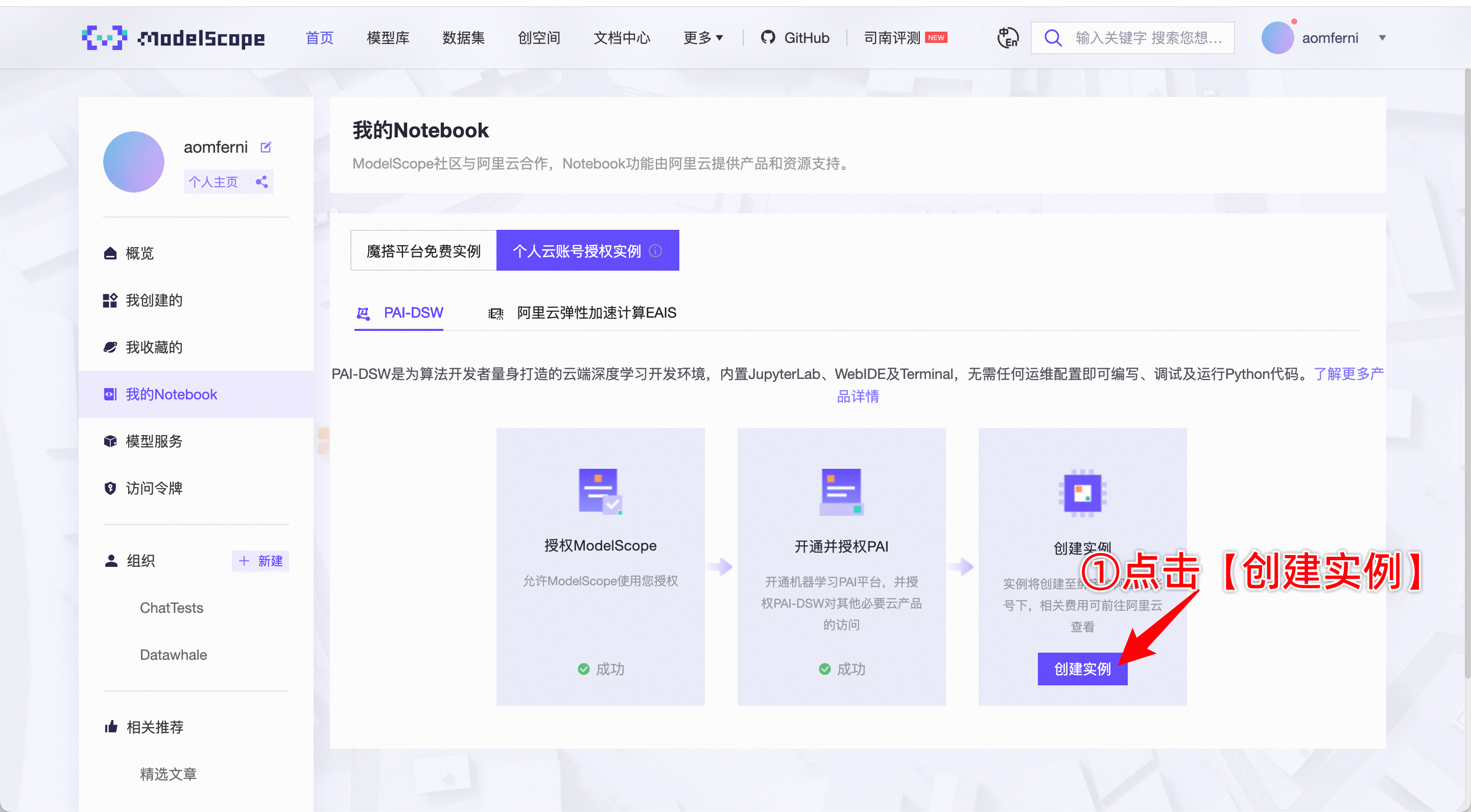
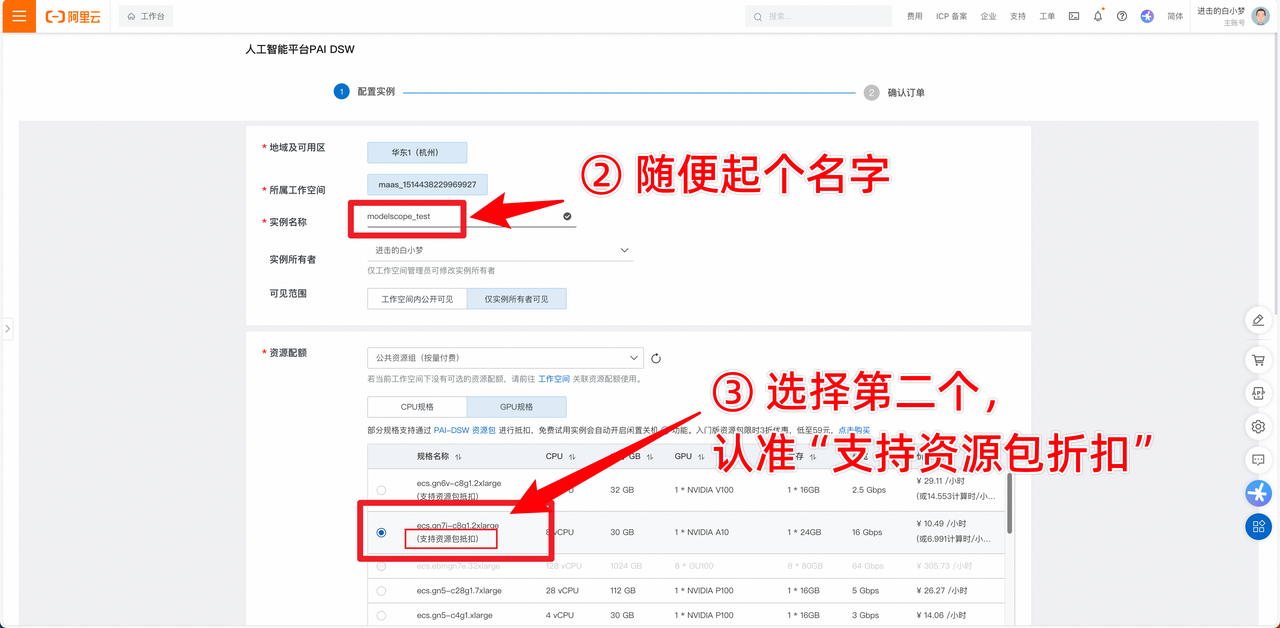
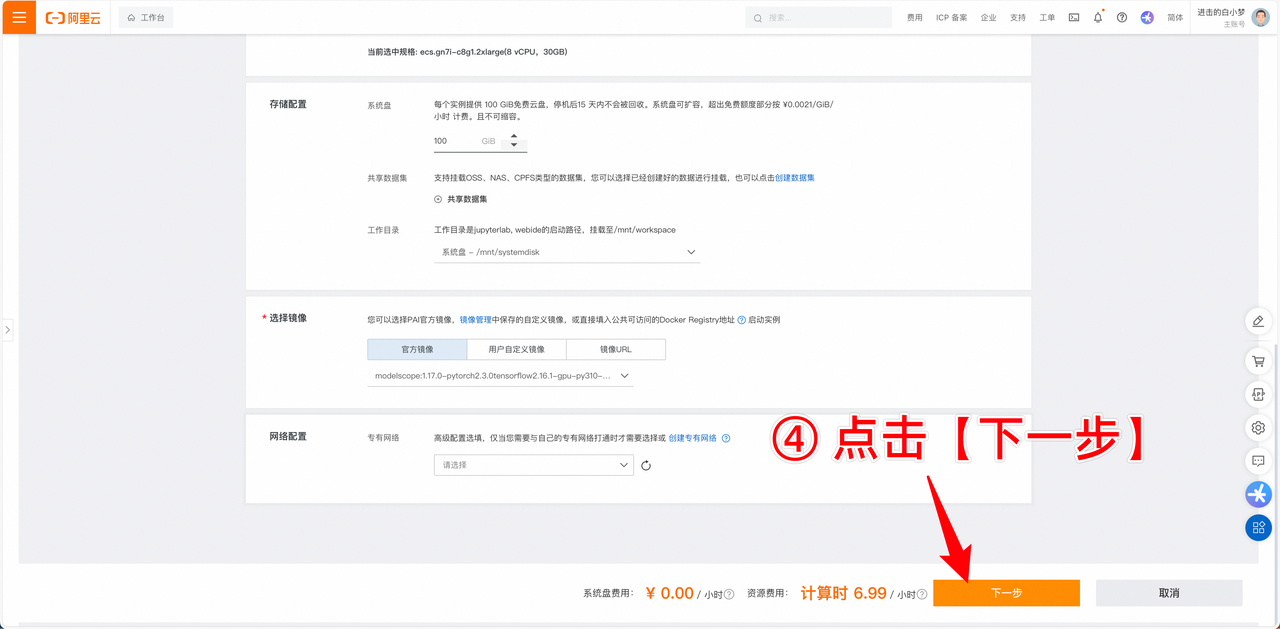
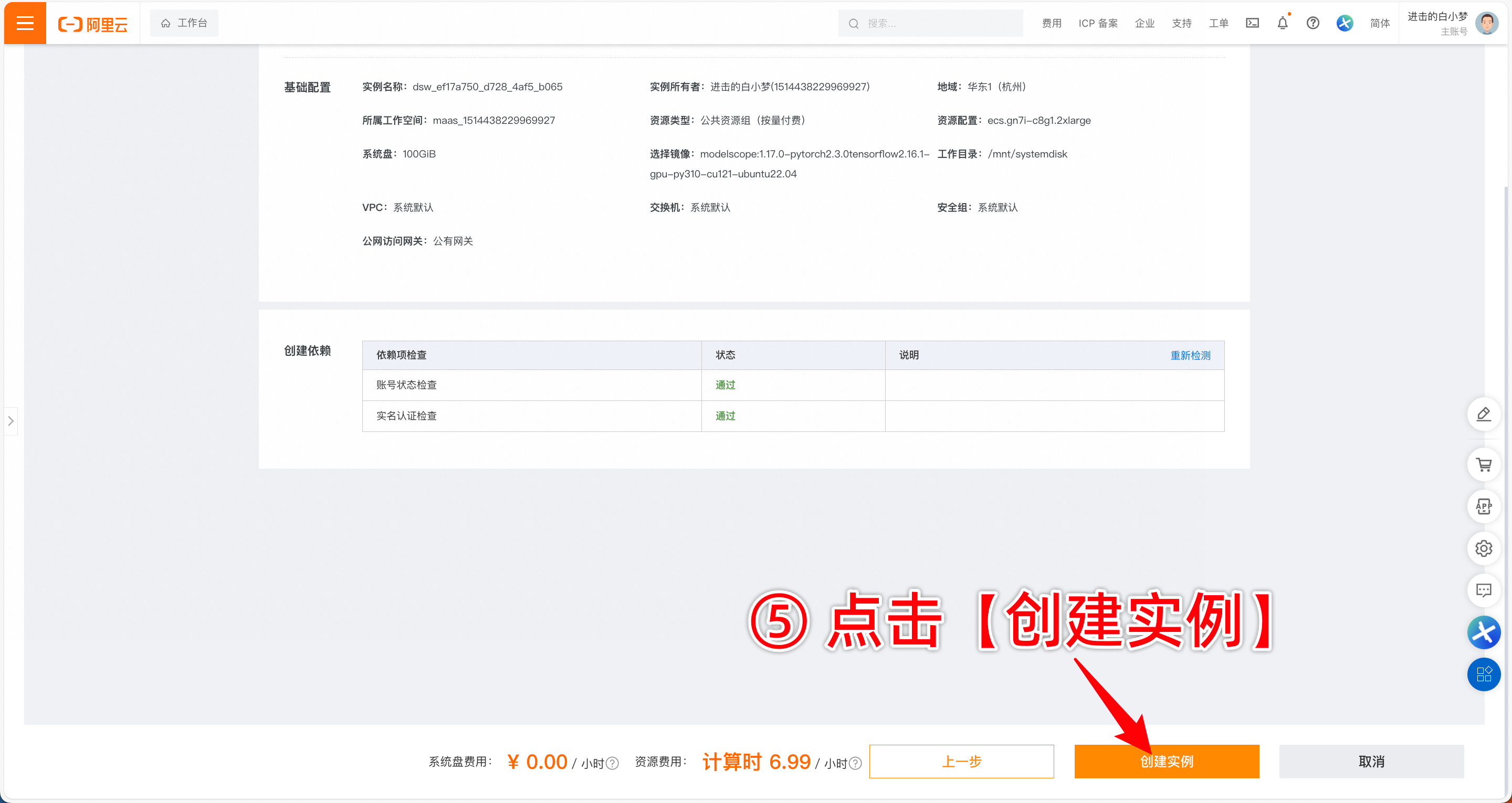
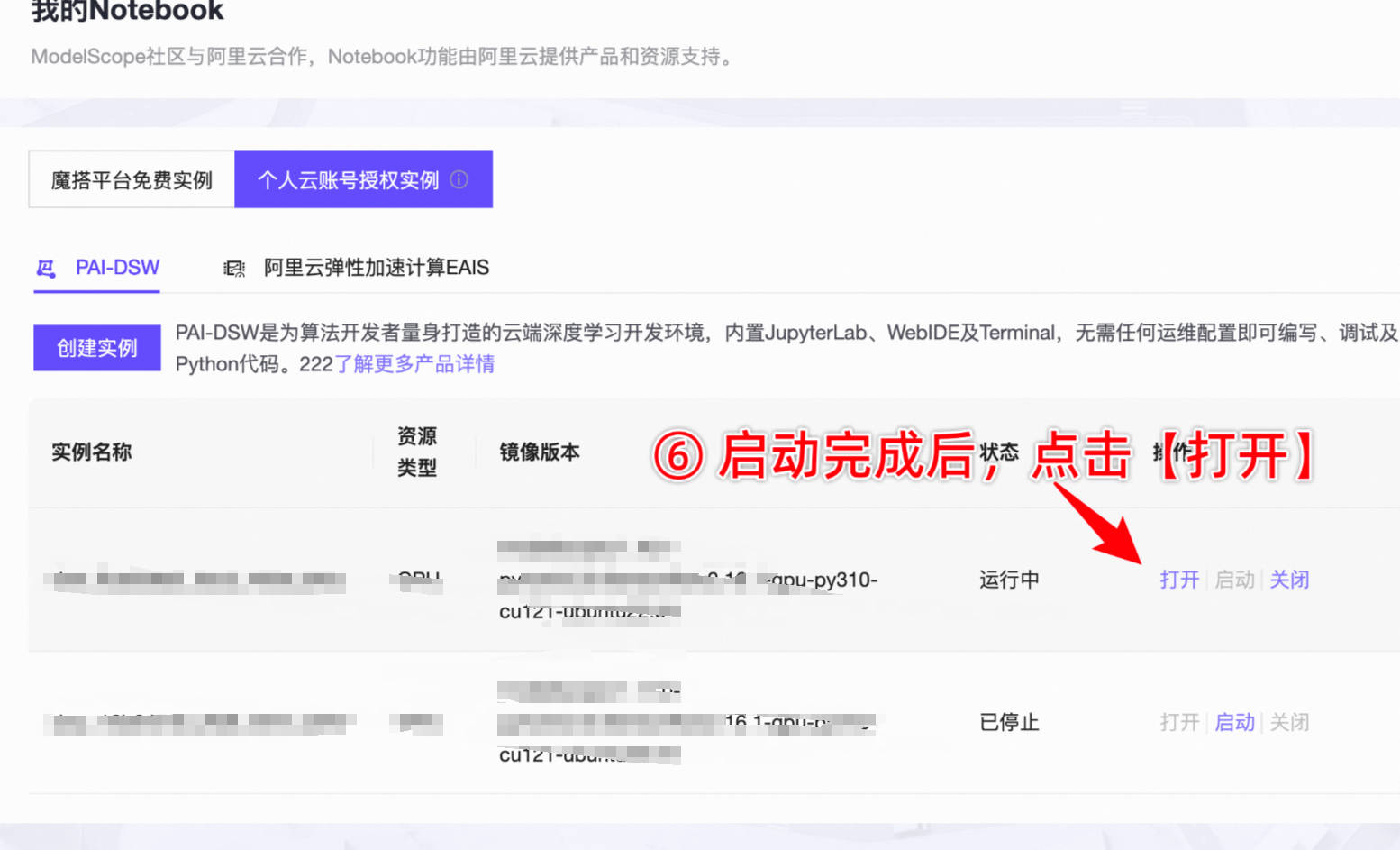
- 使用完毕后,记得关闭实例,否则计费不会停止。
趋动云使用方法
注册账号
- 访问https://www.virtaicloud.com/, 完成趋动云账号注册。
使用方法
登录服务
登录账号后,点击右上角的创建项目
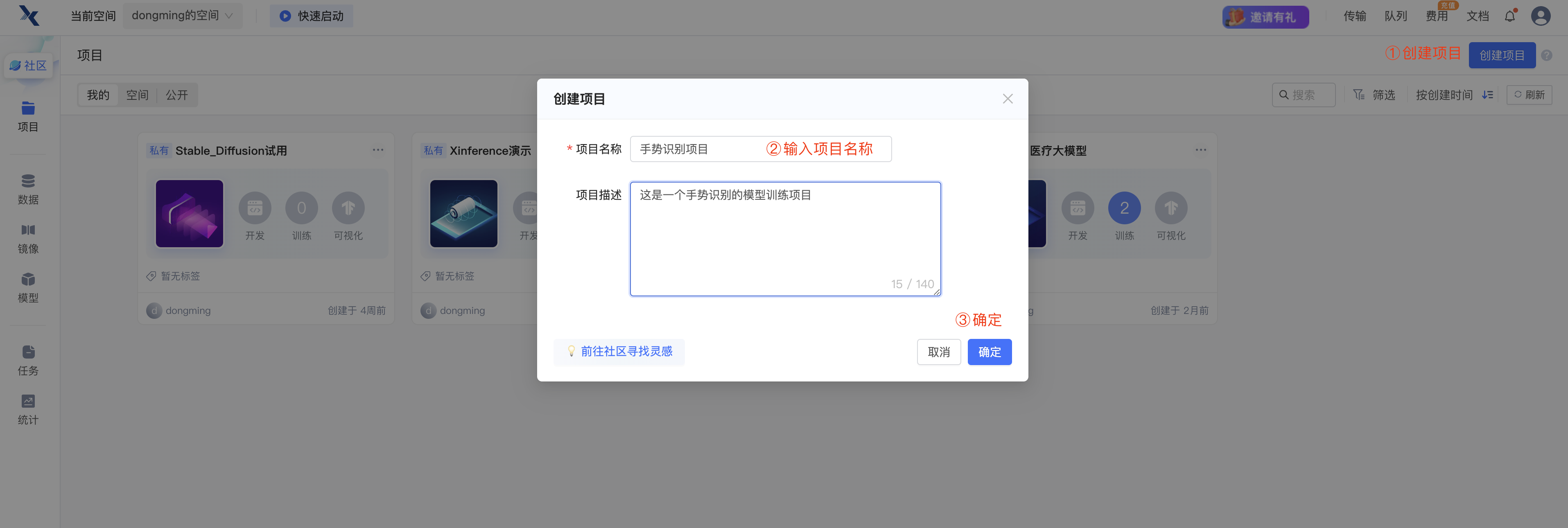
创建项目后,选择相应的机器配置以及镜像环境。
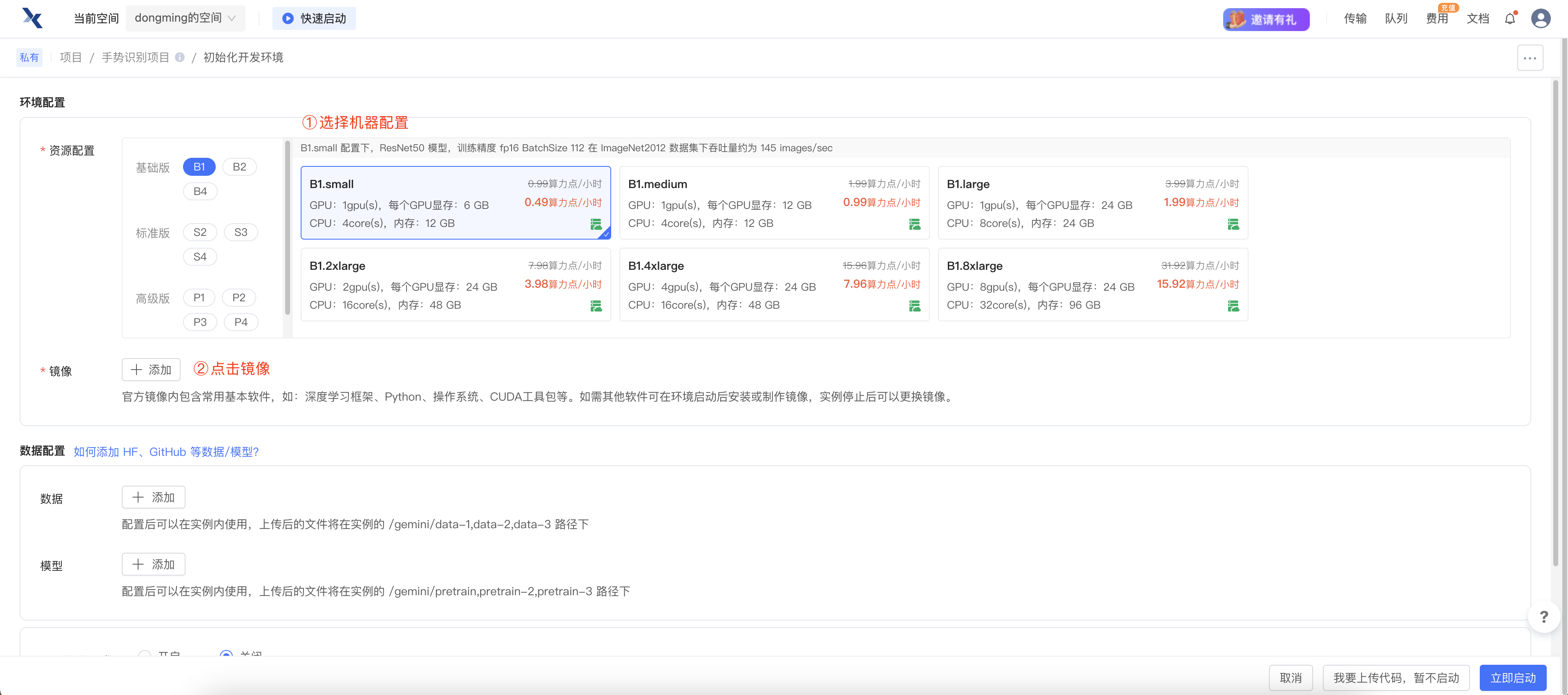
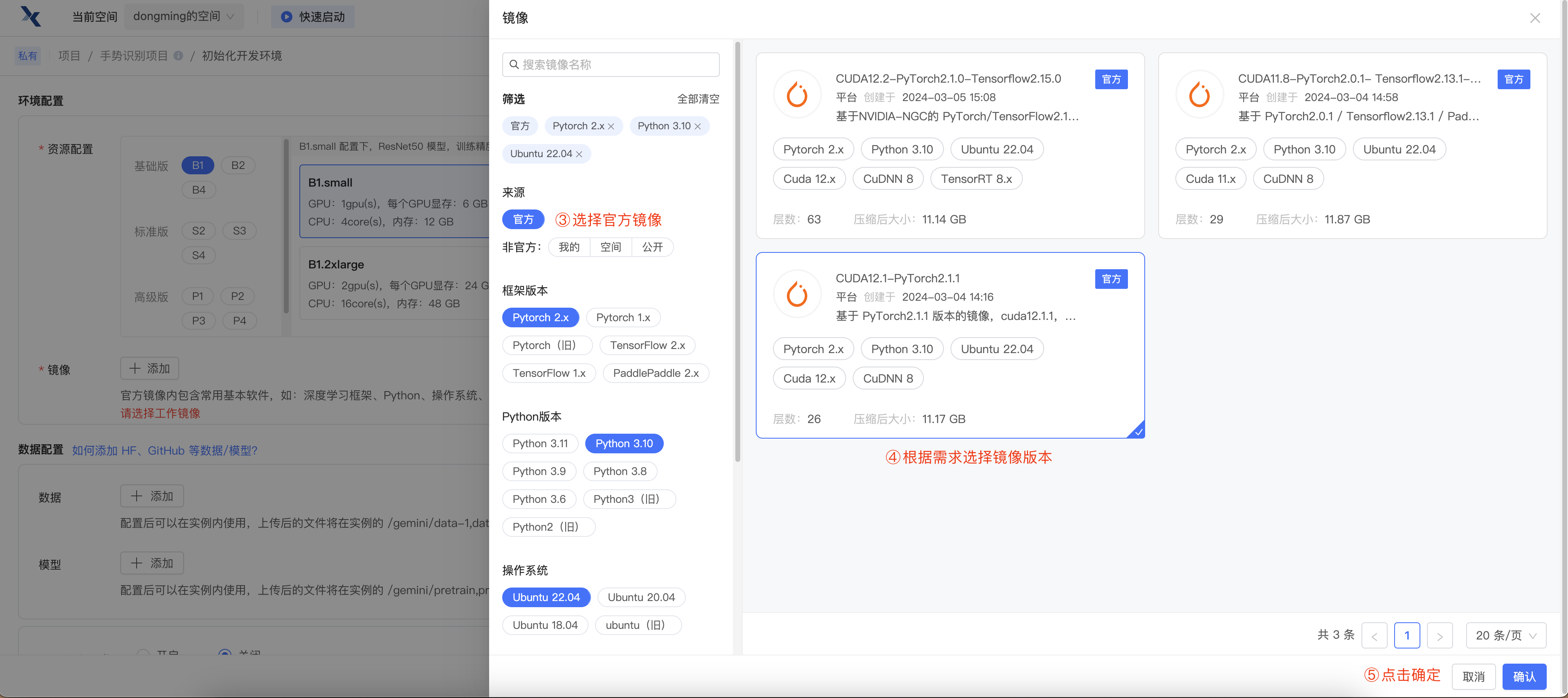
确认之后,点击立即启动。待出现 进入开发环境 按钮,点击即可进入。
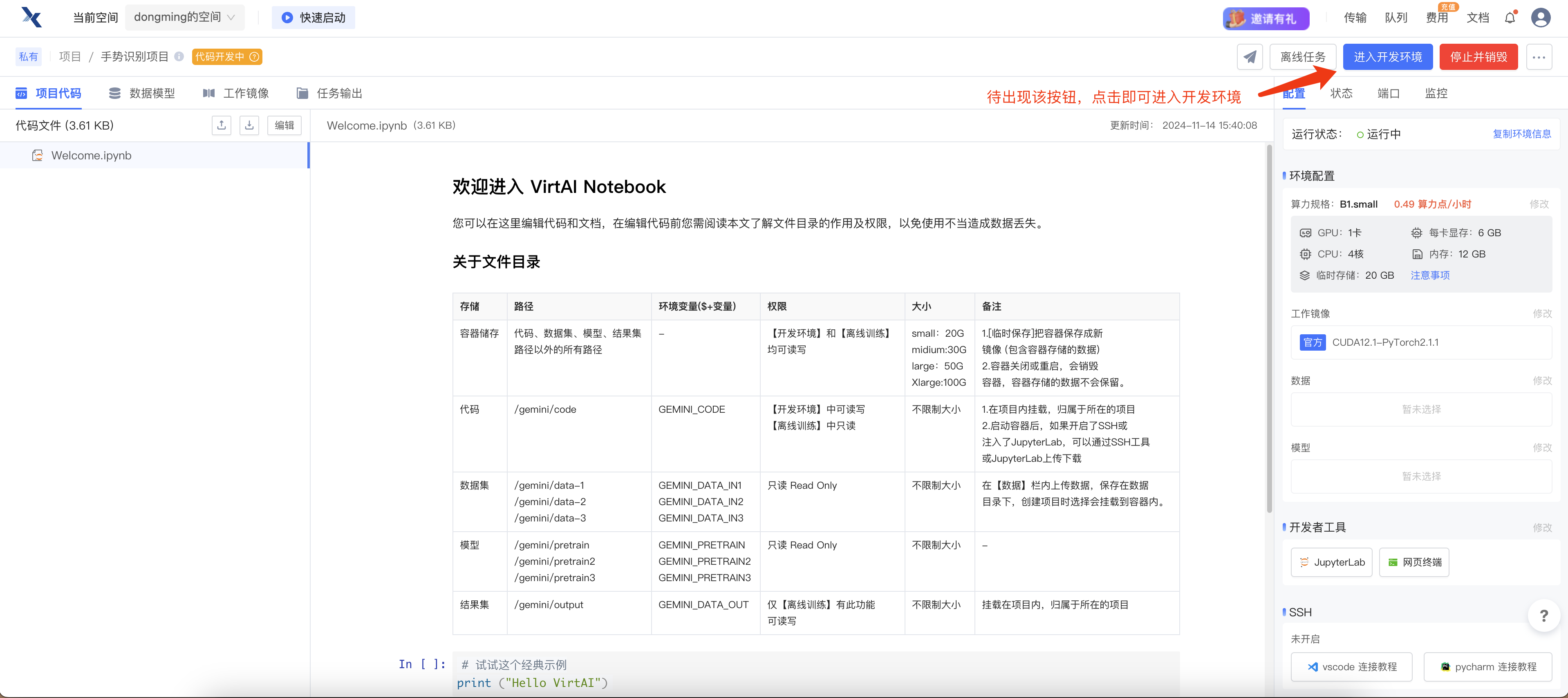
检查环境
与阿里云的检查方法类似,此处不再赘述。
准备训练框架
在趋动云平台上,由于数据存储大小限制,我们需要根据实际的场景选择不同的处理方式:
小体积情况
对于体积小的框架(例如:YOLO只有56M),可以使用pip命令安装,具体方法同阿里云的操作说明。
说明:
- 这种方式,优点是不涉及繁琐的上传流程,但是环境持久化保存(即:环境下次打开可以直接使用)有次数限制。
- 环境持久化保存的方式:在关闭环境时,选择保存环境→临时环境。
大体积情况
对于大模型(例如:Qwen模型)动辄10G以上存储空间的情况,需要使用趋动云提供的sftp上传方式来进行。
具体操作方法,请移步:【产品体验】趋动云上使用LLaMaFactory进行模型微调的流程体验一文中的 准备训练数据 和 准备训练模型 章节。
准备训练数据
同上,对于体积小的数据,可以直接使用图示中的上传文件功能。对于体积大的情况,需要使用趋动云提供的sftp上传上传方式。
此处,我们演示sftp上传的方式。
第一步:安装上传软件Xftp
https://www.xshell.com/zh/free-for-home-school/
Windows下推荐使用Xftp
Mac下推荐使用Terminus
第二步:停止并销毁趋动云环境
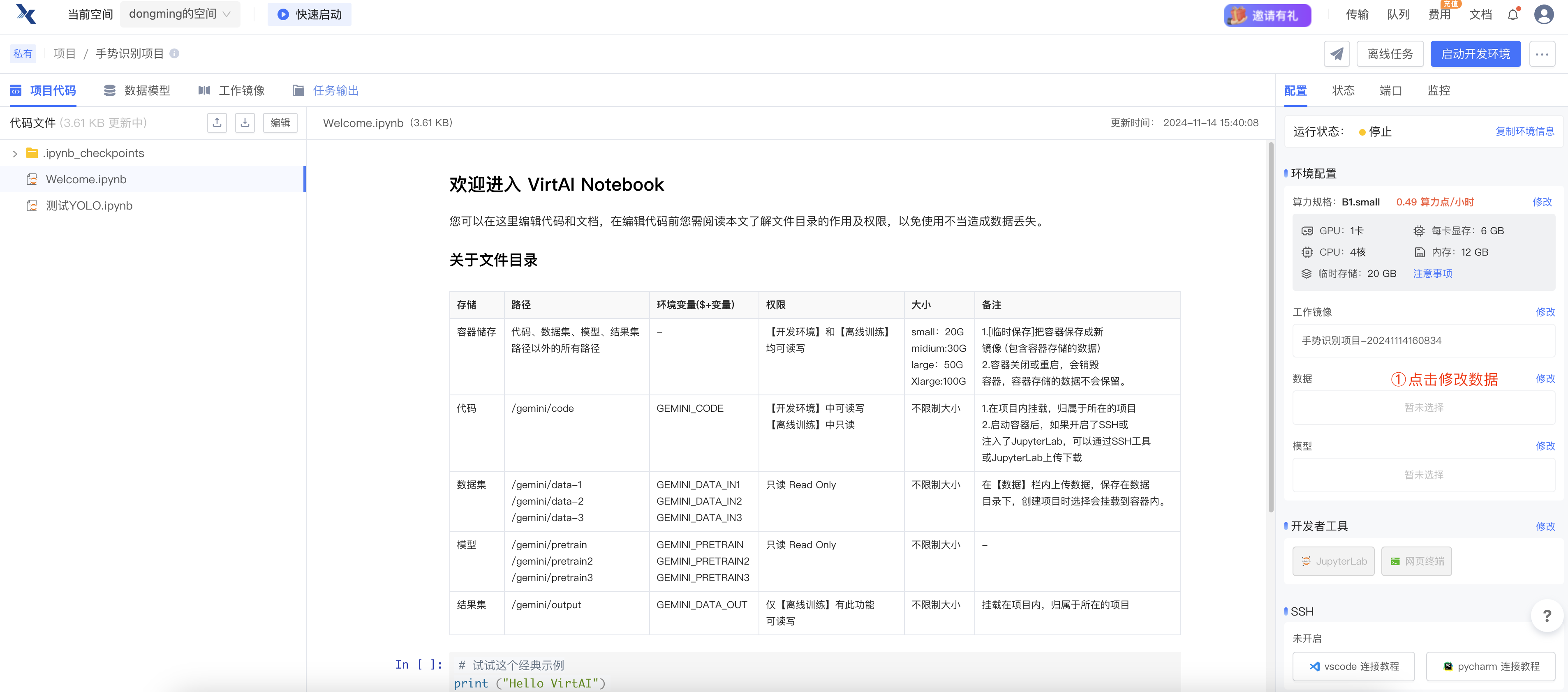
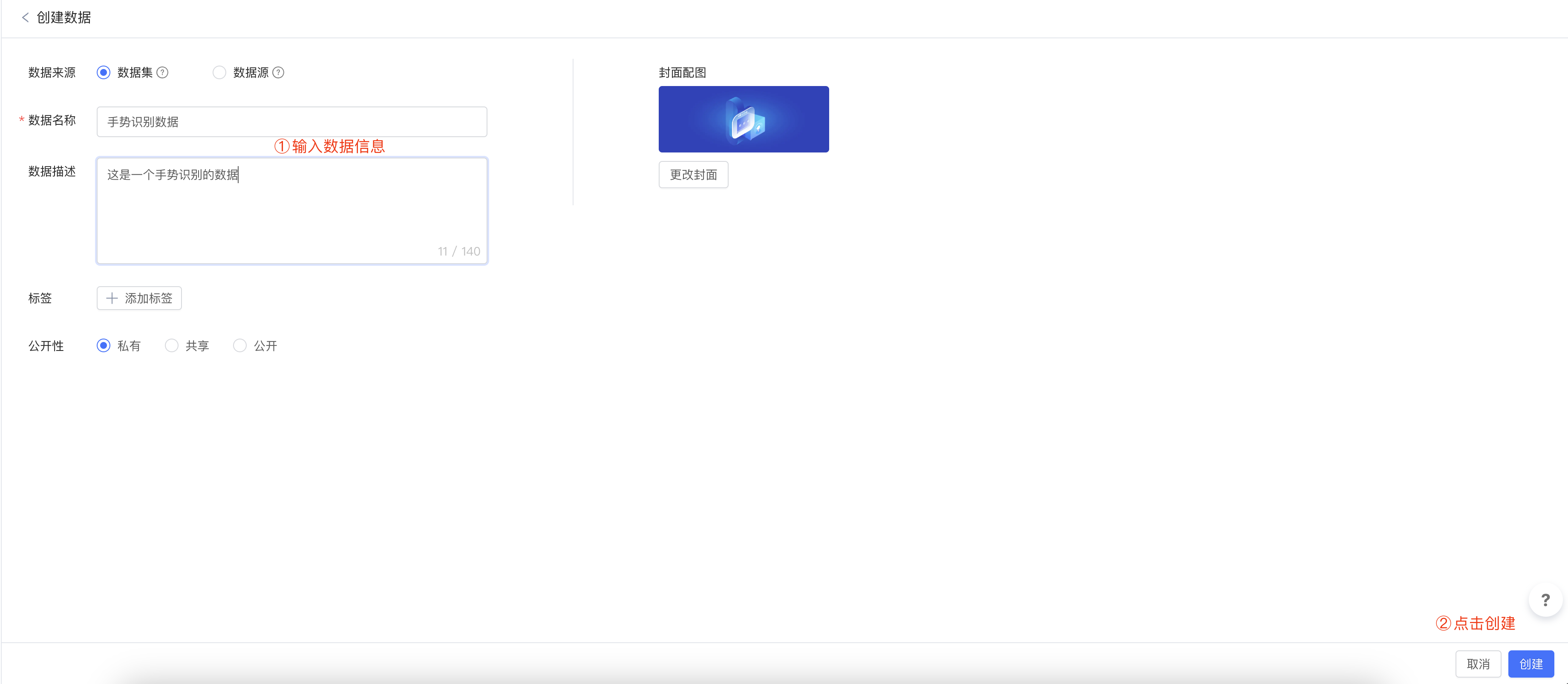
第三步:创建数据
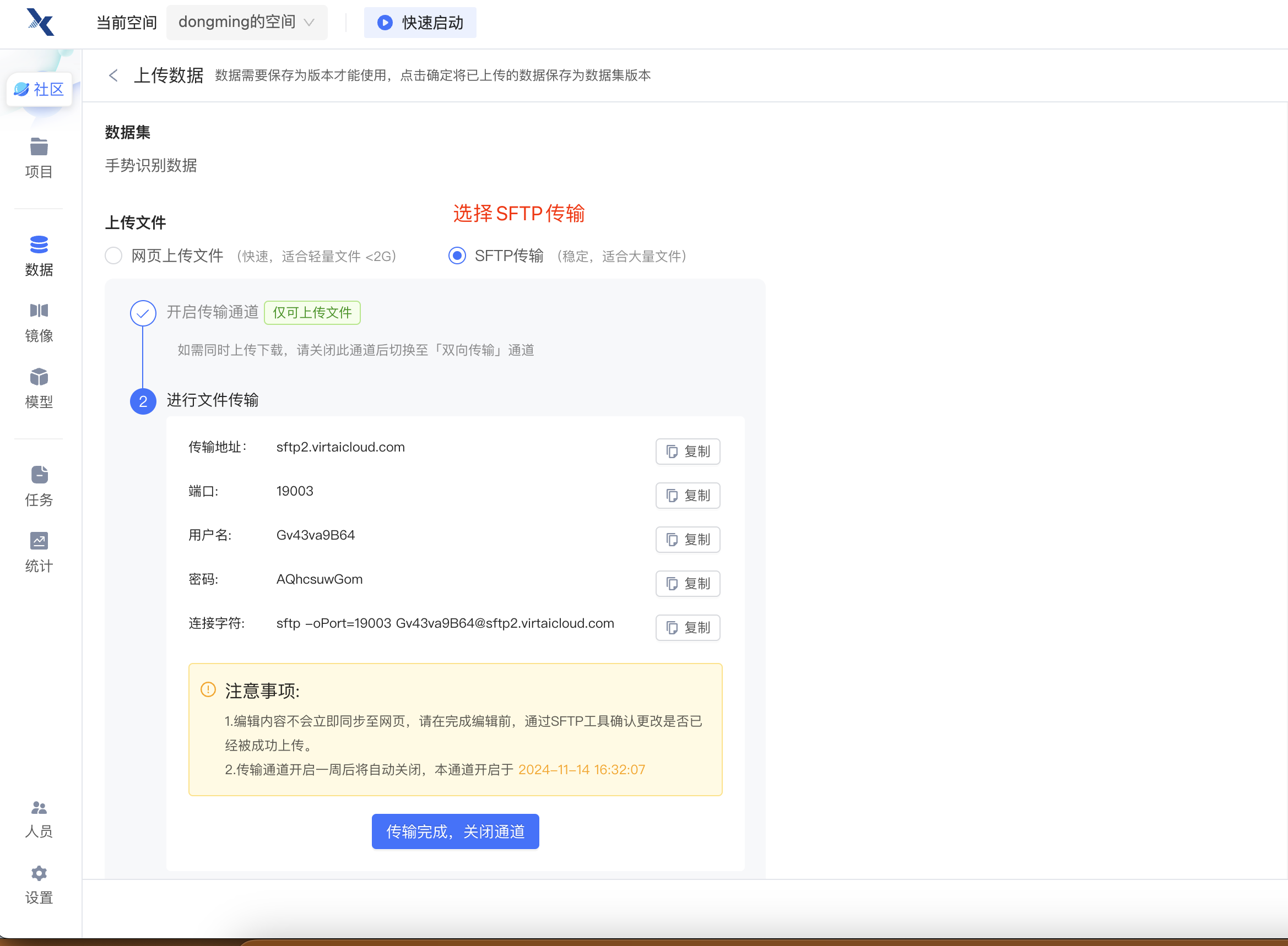
第四步:开启SFTP传输
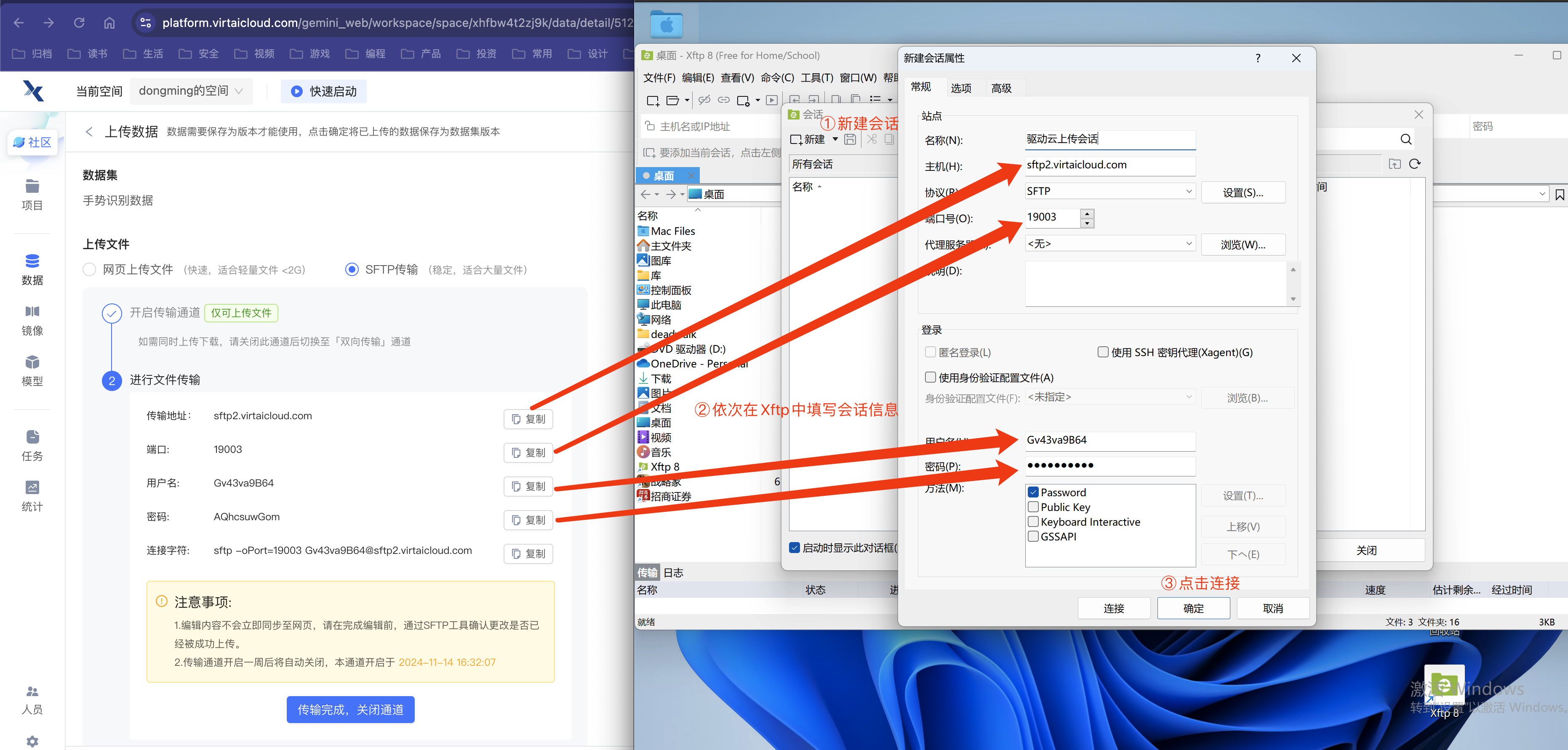
第五步:填写连接信息后开始连接
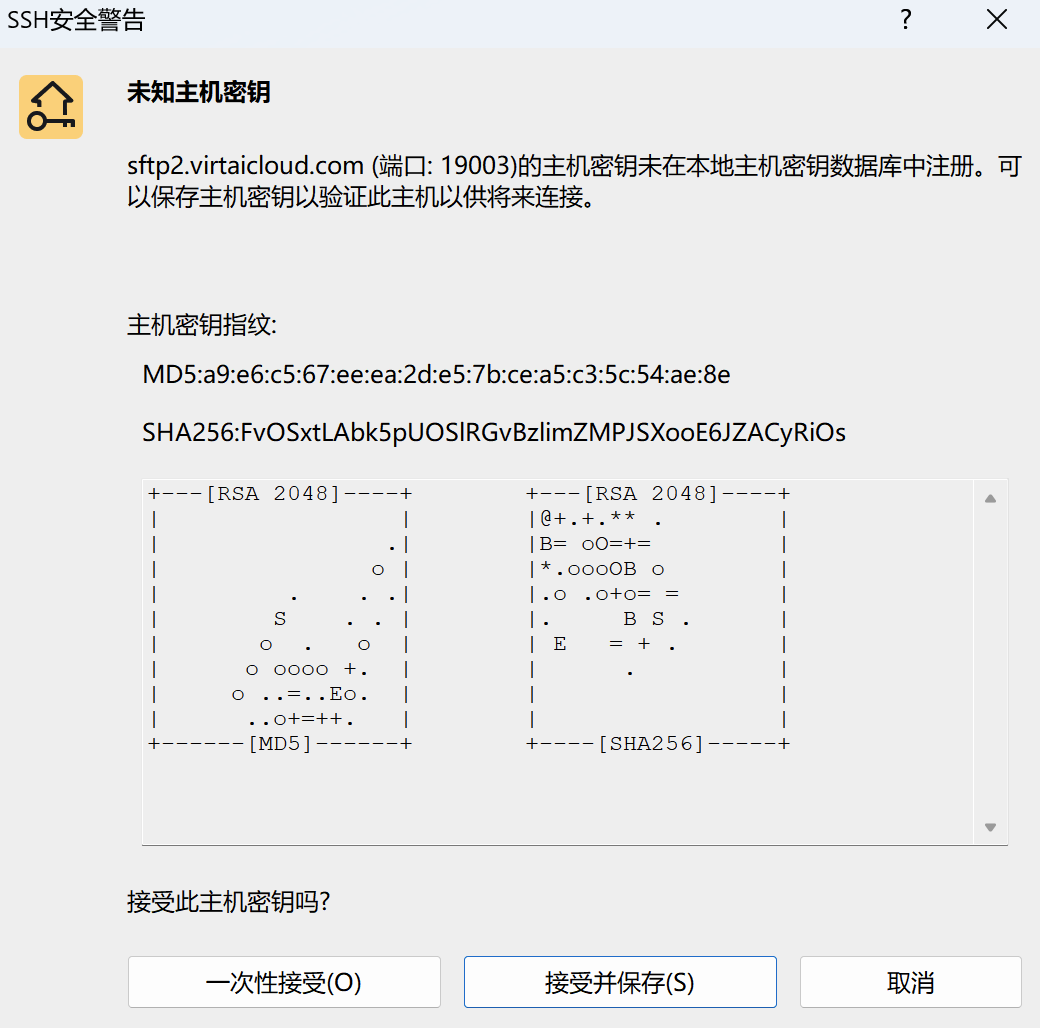
第六步:上传数据
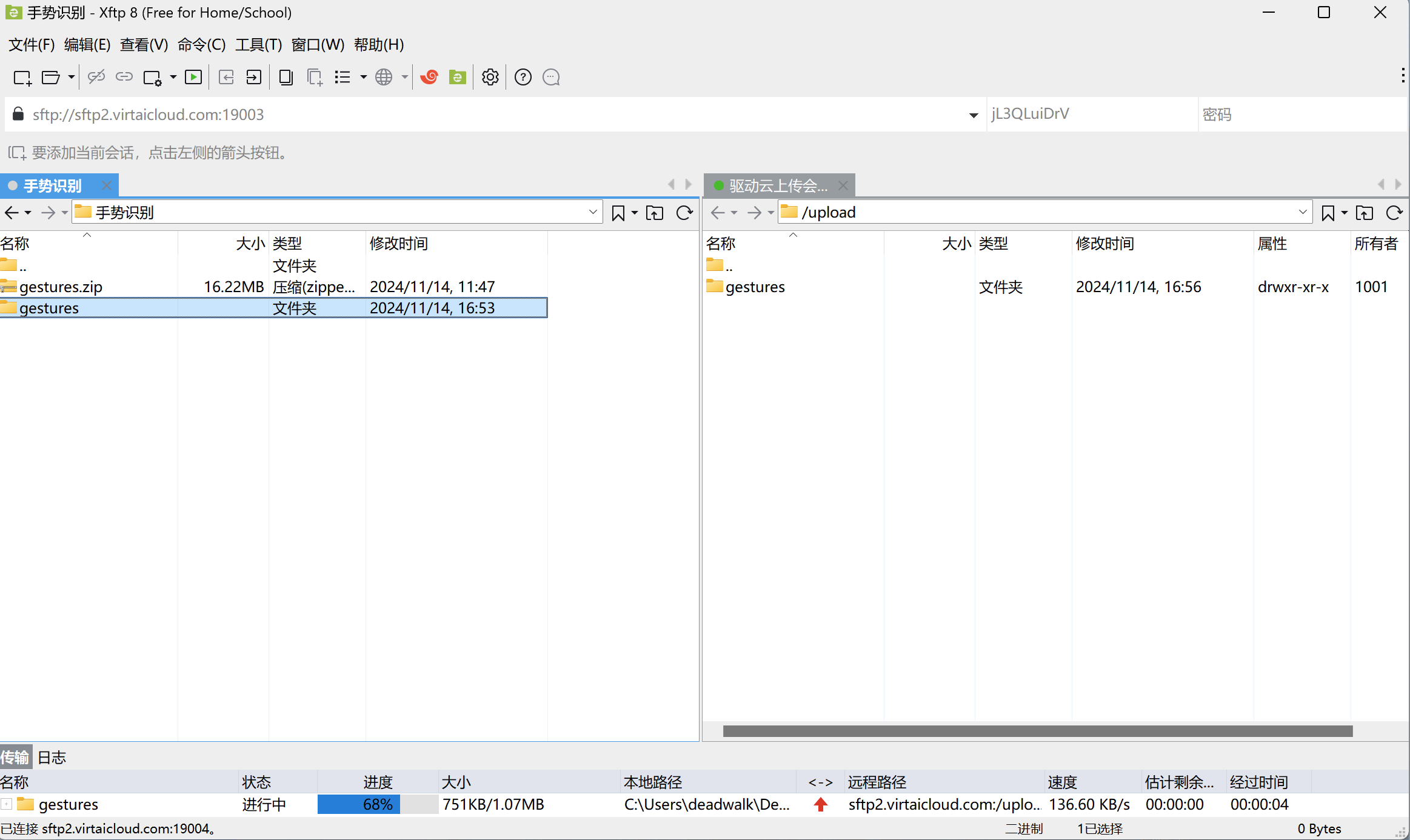
上传后文件后,在页面上可以使用趋动云的在线解压,以便未来加载数据集时直接使用。
第七步:上传完毕后,在趋动云页面中关闭传输通道并进行确定操作
第八步:修改项目中的数据选项,重新启动开发环境即可
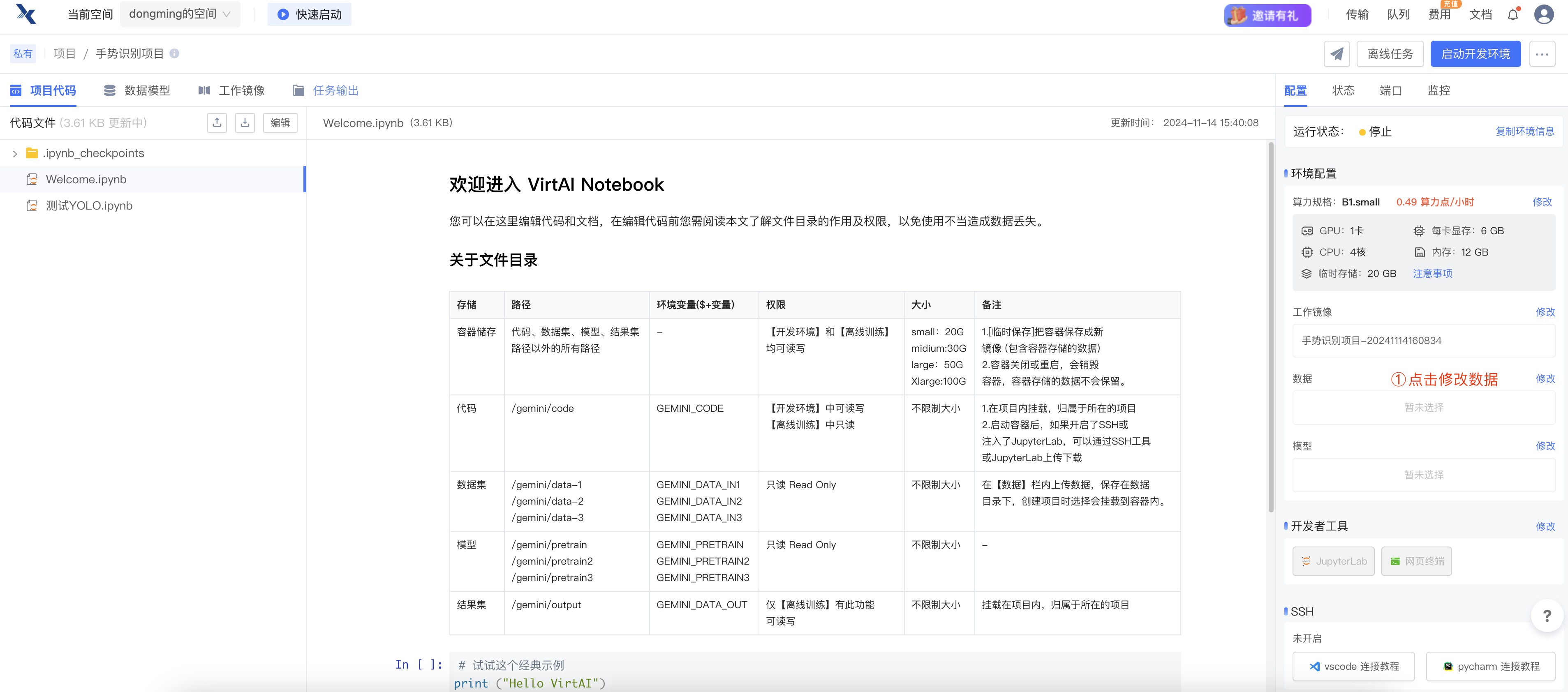
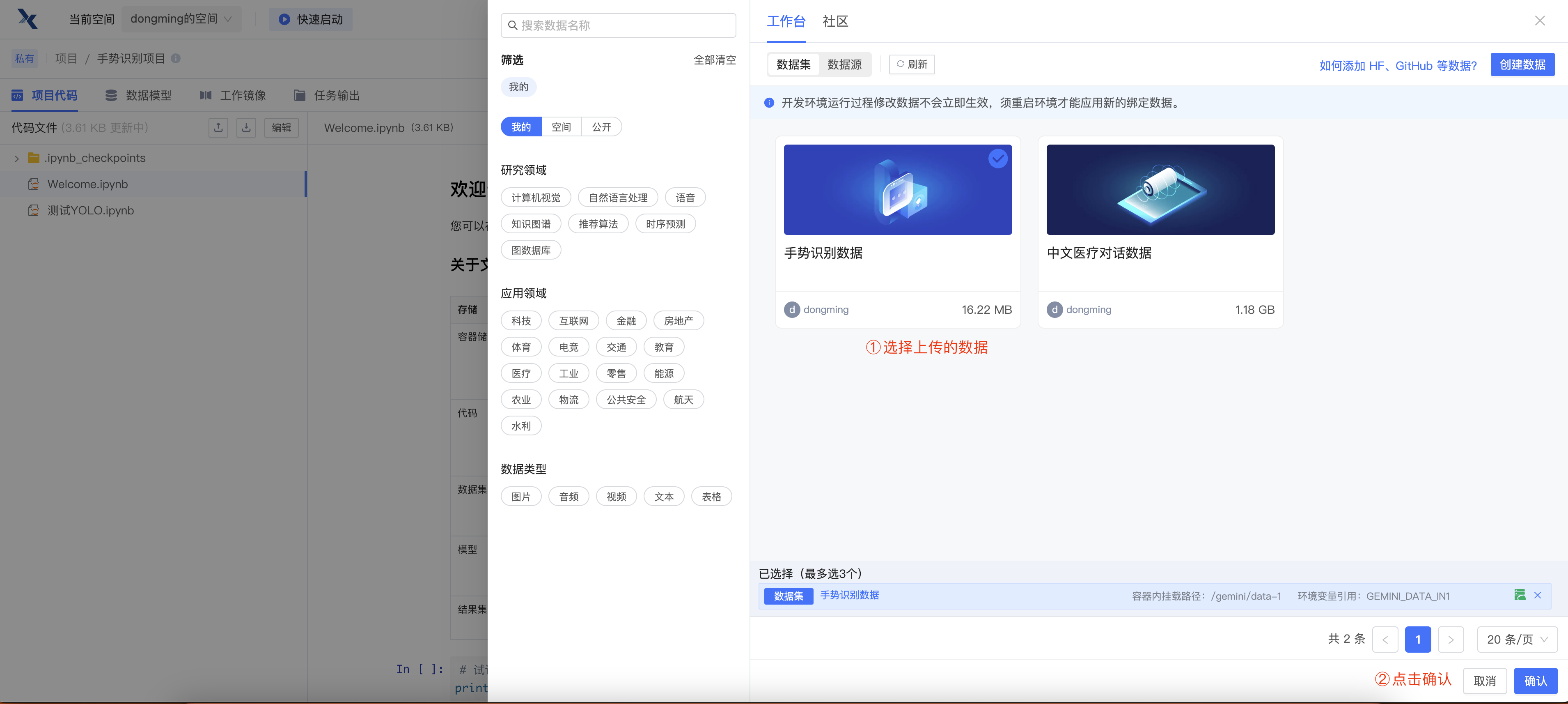
第九步:按照官方提示,切换到 /gemini/data-1 目录,即可查看到上传的数据。
趋动云最近更新增加了导出数据/模型的功能,相较于上述操作更为简便,篇幅原因不做详细说明,感兴趣的同学可以查看导出为数据/模型
开始训练
新建notebook后,配置对应目录的数据路径
from ultralytics import YOLO
# 1,构建模型
model = YOLO("yolov8n-cls.yaml")
if __name__ == "__main__":
# 2,训练模型
results = model.train(data="/gemini/data-1/gestures/gestures",
epochs=100,
imgsz=128,
batch=8
)完成训练
训练完毕后,在notebooke同目录下会生成runs目录。
如果希望把训练结果下载到本地,可以使用zip命令打包后下载。
# 基本语法:zip [选项] [打包后的文件名] [要打包的文件或目录列表]
zip -r runs.zip runs
注意事项
- /gemini/code目录是可以读写的,但是/gemini/data等其他目录只能读,不能写。
- /gemini/code目录的数据,在销毁环境后是可以保留的,但是不建议在云端保存。
- 如果
关闭环境时没有选择保存临时环境,那么安装过的依赖会重置,在下次启动时需要重新安装。
常见问题
问题1:通过pip install -e . 安装ultralytics后使用,提示cannot import name 'YOLO' from 'ultralytics' (unknown location)
在阿里云和趋动云上,使用pip编辑模式下安装ultralytics会遇到此问题,具体原因未明,Github上有issue仍在讨论中。YOLO官网给出的安装方式是直接用pip方式安装。
解决办法:
pip install ultralytics 方式安装。问题2:我的云环境重新启动后,运行YOLO的代码,提示No module named 'ultralytics',请问是什么原因?
云环境重启之后,一般会重置环境,导致之前安装的依赖不存在了。
解决办法:
1. 可以通过`pip list`命令进一步排查是否有ultralytics。
2. 如果没有ultralytics,则重新使用pip命令安装即可。问题3:在趋动云环境里,我上传的数据会不会在关闭云服务器后丢失?
趋动云环境中,/gemini/code目录是可以保留数据的,即服务关闭再打开,该目录下的数据是保留上次的。
不过,建议重要的数据、代码在本地维护保存,云环境只作为临时环境训练模型使用。问题4:在阿里云环境里,我上传的数据会不会在关闭云服务器后丢失?
阿里云环境的/mnt/workspace/目录,经测试数据会进行保留。不过,我们还是建议重要数据、代码在本地维护保存。问题5:使用YOLO进行模型训练时,脚本提示RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
PytorchStreamReader一般是从github上下载权重时文件存在异常,导致torch.load时报错。
解决方法:
1. 删除已经下载的yolo**.pt文件
2. 运行训练脚本,重新下载.pt文件
或者
1. 手动下载yolo**.pt文件
2. 通过云环境的上传文件将.pt文件上传,再运行训练脚本。


1人评论了“【操作攻略】GPU云环境的使用介绍”
测试评论功能